Ukrywaliśmy już pliki, wiadomość i obrazki w różnych miejscach. Siłą rzeczy następnym miejscem, w którym ukryjemy nasze elementy, będą pliki dźwiękowe, do najprostszych, jeśli chodzi o strukturę, należy format WAVE. Jest on bardzo podobny do struktury formatu pliku BMP, do zapisu i odczytania danych używana jest konwersja bezstratna, dlatego możemy bez przeszkód, manipulować tymi danymi nie martwiąc się, że po ich zmianie dane ulegną uszkodzeniu lub będą błędnie odczytane. Plik WAVE składa się z trzech głównych elementów:
Nagłówek RIFF:

Podkategoria „fmt” opisuje format danych dźwiękowych:
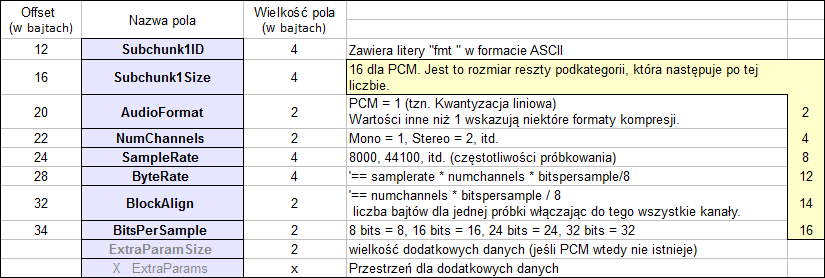
Podkategoria „danych” zawiera rozmiar danych i rzeczywisty dźwięk:

Czasem występuje również podkategoria JUNK, która nadaje się do ukrycia tekstu w bardzo prosty sposób. W dalszej części pokaże algorytm, który będzie dodawał takie pola. Kategoria ta może występować zarówno po RIFF, jak i po „fmt „:

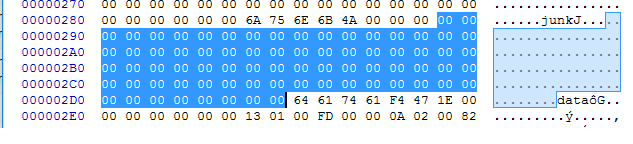
Można ją wygenerować sztucznie i wpisać w niej cokolwiek tylko chcemy, z zachowaniem pewnych zasad. Przykładowy program pozwalający na ukrycie pliku w bajtach nagłówka JUNK:
Imports System.Windows.Forms
Module Module1
Sub Main()
'Otwiera dialog z użytkownikiem
Console.WriteLine("Co chesz zrobić? Wpisz cyfrę zadania." + vbNewLine + "1.Wydobądź ukryty plik." _
+ vbNewLine + "2.Ukryj plik.")
Dim zad As String
Do
zad = Console.ReadLine()
If zad = "1" Or zad = "2" Then
Exit Do
Else
Console.WriteLine("możesz wybrać tylko cyfrę 1 lub 2.")
End If
Loop
Dim open_dialog As New OpenFileDialog()
open_dialog.InitialDirectory = "c:\"
open_dialog.Filter = "Image Files (*.wav)| *.wav"
If open_dialog.ShowDialog() = System.Windows.Forms.DialogResult.OK Then
If zad = 2 Then
''Ukrywanie pliku
Dim File_bytes As Byte() = IO.File.ReadAllBytes(open_dialog.FileName)
Dim plikDoUkrycia As New OpenFileDialog()
plikDoUkrycia.InitialDirectory = "c:\"
plikDoUkrycia.Filter = "All Files|*.*"
If plikDoUkrycia.ShowDialog() = System.Windows.Forms.DialogResult.OK Then
Dim File_DoUkrycia As Byte() = IO.File.ReadAllBytes(plikDoUkrycia.FileName)
'tworzymy nagłówek Junk wraz z wielkością pliku ukrywanego
Dim naglowekJunk() As Byte = System.Text.Encoding.ASCII.GetBytes("JUNK")
Dim wielkoscJunk() As Byte = System.BitConverter.GetBytes(File_DoUkrycia.Count)
'kopiujemy poczatek bajtów pliku oryginalnego (12 bajtów nagłówka RIFF
Dim poczatek(12) As Byte
Array.Copy(File_bytes, poczatek, 12)
'Tworzy nową tablicę o wielkośći połączonych ilości bajtów pliku kontenera,
' pliku ukrywanego i 8 bajtów dla slowa JUNK i wielkości dla pliku ukrywanego
Dim nowyplik(File_bytes.Count + File_DoUkrycia.Count + 7) As Byte
'kopiuje RIFF
Array.Copy(poczatek, nowyplik, poczatek.Count)
'kopiuje JUNK i wielkość pliku ukrywanego
Array.Copy(naglowekJunk, 0, nowyplik, 12, naglowekJunk.Count)
Array.Copy(wielkoscJunk, 0, nowyplik, 16, wielkoscJunk.Count)
'kopiuje bajty pliku ukrywanego
Array.Copy(File_DoUkrycia, 0, nowyplik, 20, File_DoUkrycia.Count)
'kopiuje reszte bajtów kontenera
Array.Copy(File_bytes, 12, nowyplik, 20 + File_DoUkrycia.Length, File_bytes.Count - 12)
Console.Write("Podaj nazwę pliku pod którym chcesz zapisać plik wav: ")
Dim nazwapliku As String = Console.ReadLine()
IO.File.WriteAllBytes("C:\Users\piotr\Desktop\" + nazwapliku + ".wav", nowyplik)
Console.WriteLine("Bajty zostały ukryte. Zapisano plik: " + "C:\Users\piotr\Desktop\" +
nazwapliku + ".wav")
End If
Console.ReadLine()
Else
'przygotowanie pliku
Dim listaBajtowPlikuUkrytego As New List(Of Byte)
Dim wielkoscPliku As Integer = 0
'otwórz wskazany plik
Dim wavefile() As Byte = IO.File.ReadAllBytes(open_dialog.FileName)
Dim memstream As New IO.MemoryStream(wavefile)
'czytaj wszystkie bajty pliku
Using binreader As New IO.BinaryReader(memstream)
Do
'czytaj do czasu aż natrafisz na 'JUNK' lub 'junk'
Dim Junk As String = BitConverter.ToString(binreader.ReadBytes(4), 0)
If (Junk = "6A-75-6E-6B" Or Junk = "4A-55-4E-4B") Then
'pobierz wielkość pliku ukrytego
wielkoscPliku = BitConverter.ToInt32(binreader.ReadBytes(4), 0)
Exit Do
End If
Loop
'zapisz bajty pliku ukrytego do listy
For i As Integer = 0 To wielkoscPliku - 1
listaBajtowPlikuUkrytego.Add(binreader.ReadByte)
Next
End Using
'stwórz nową tablicę
Dim nowyplik() As Byte = listaBajtowPlikuUkrytego.ToArray()
'Podaj nazwę pliku
Console.WriteLine()
Console.Write("Podaj nazwę pliku pod którycm chcesz zapisać plik: ")
Dim nazwapliku As String = Console.ReadLine()
'zapisz plik
IO.File.WriteAllBytes("C:\Users\piotr\Desktop\" + nazwapliku, nowyplik)
Console.WriteLine("Bajty zostały odzyskane. Zapisano plik: " + "C:\Users\piotr\Desktop\" + nazwapliku)
Console.ReadLine()
End If
End If
End Sub
End Module
Taki program pobiera bajty pliku kontenera, oddziela dwanaście pierwszych bajtów i dodaje cztery bajty JUNK, wielkość bajtów pliku ukrytego, a następnie bajty ukrytego pliku i resztę bajtów kontenera. Pierwsza opcja pozwala na pobranie i zapis tych bajtów. Jeśli plik ukrywany nie jest duży, może zdezorientować analityka, który potraktuje te sekcje jako śmieci. Kolejną metodą dodania dodatkowych bajtów do kontenera jest przekształcenie nagłówka „fmt” przekształcając Subchunk1size, ExtraParamSize i ExtraParams:
Imports System.Windows.Forms
Module Module1
Sub Main()
'Otwiera dialog z użytkownikiem
Console.WriteLine("Co chesz zrobić? Wpisz cyfrę zadania." + vbNewLine + "1.Wydobądź ukryty plik." _
+ vbNewLine + "2.Ukryj plik.")
Dim zad As String
Do
zad = Console.ReadLine()
If zad = "1" Or zad = "2" Then
Exit Do
Else
Console.WriteLine("możesz wybrać tylko cyfrę 1 lub 2.")
End If
Loop
Dim open_dialog As New OpenFileDialog()
open_dialog.InitialDirectory = "c:\"
open_dialog.Filter = "Image Files (*.wav)| *.wav"
If open_dialog.ShowDialog() = System.Windows.Forms.DialogResult.OK Then
If zad = 2 Then
''Ukrywanie pliku
Dim File_bytes As Byte() = IO.File.ReadAllBytes(open_dialog.FileName)
Dim plikDoUkrycia As New OpenFileDialog()
plikDoUkrycia.InitialDirectory = "c:\"
plikDoUkrycia.Filter = "All Files|*.*"
If plikDoUkrycia.ShowDialog() = System.Windows.Forms.DialogResult.OK Then
Dim File_DoUkrycia As Byte() = IO.File.ReadAllBytes(plikDoUkrycia.FileName)
Dim poczatek(16) As Byte
Array.Copy(File_bytes, poczatek, 16)
Dim wielkoscPoczatkowa() As Byte = {File_bytes(16), File_bytes(17), File_bytes(18), File_bytes(19)}
'Jeśli plik nie zawiera dodatkowych danych (Subchunk1Size = 16)
If BitConverter.ToString(wielkoscPoczatkowa, 0) = "10-00-00-00" Then
'pobiera początkowe 18 bajtów
Dim wielkoscFMT() As Byte = System.BitConverter.GetBytes(File_DoUkrycia.Count + 18)
wielkoscPoczatkowa = wielkoscFMT
'Tworzymy nową tablicę o wielkośc pliku i pliku ukrywanego + 2 bajty dla ExtraParamSize
Dim nowyplik(File_bytes.Count + File_DoUkrycia.Count + 2) As Byte
' kopiujemy początek do noewgo pliku
Array.Copy(poczatek, nowyplik, poczatek.Count)
'nadajemy nową wartość dla Subchunk1Size
Array.Copy(wielkoscPoczatkowa, 0, nowyplik, 16, wielkoscPoczatkowa.Count)
'dodajemy 16 bajtów nagłówka fmt
Array.Copy(File_bytes, 20, nowyplik, 20, 16)
'tworzymy wielkość dla ExtraParamSize
Dim wielkoscPliku As Short
Try 'wielkość ta jes dwu bajtowa więc nasz pli nie może mieć więcej niż (FF FF) bajtów czyli 65535
wielkoscPliku = File_DoUkrycia.Length
Catch ex As Exception
Console.WriteLine("Twój plik jest za duży. Można ukryć tylko pliki nie większe niż: " + Short.MaxValue.ToString + " bajtów" + vbNewLine +
" twój plik zawiera: " + File_DoUkrycia.Length.ToString + " bajtów")
Exit Sub
End Try
'dodajemy ExtraParamSize
Array.Copy(System.BitConverter.GetBytes(wielkoscPliku), 0, nowyplik, 36, 2)
'dodajemy bajty pliku do ukrycia
Array.Copy(File_DoUkrycia, 0, nowyplik, 38, File_DoUkrycia.Count)
'dodajemy resztę bajtów pliku kontenera
Array.Copy(File_bytes, 36, nowyplik, 38 + File_DoUkrycia.Length, File_bytes.Count - 36)
'zapisujemy plik
Console.Write("Podaj nazwę pliku pod którym chcesz zapisać plik wav: ")
Dim nazwapliku As String = Console.ReadLine()
IO.File.WriteAllBytes("C:\Users\piotr\Desktop\" + nazwapliku + ".wav", nowyplik)
Console.WriteLine("Bajty zostały ukryte. Zapisano plik: " + "C:\Users\piotr\Desktop\" +
nazwapliku + ".wav")
Else
Console.WriteLine("Twój plik już zawieje dodatkowe parametry.")
End If
End If
Console.ReadLine()
Else
'przygotowanie pliku
Dim listaBajtowPlikuUkrytego As New List(Of Byte)
Dim wavefile() As Byte = IO.File.ReadAllBytes(open_dialog.FileName)
Dim wielkoscPoczatkowa() As Byte = {wavefile(16), wavefile(17), wavefile(18), wavefile(19)}
'sprawdzamy czy Subchunk1Size = 16 jesli nie to
If Not BitConverter.ToString(wielkoscPoczatkowa, 0) = "10-00-00-00" Then
'pobieramy wielkość ukrytego pliku
Dim wielkoscPlikuUkrytego As Short = BitConverter.ToInt16({wavefile(36), wavefile(37)}, 0)
'dodajemy bajty ukrytego pliku do listy
For i As Integer = 38 To 38 + wielkoscPlikuUkrytego - 1
listaBajtowPlikuUkrytego.Add(wavefile(i))
Next
End If
'tworzymy nową tablicę
Dim nowyplik() As Byte = listaBajtowPlikuUkrytego.ToArray()
'Podaj nazwę pliku
Console.WriteLine()
Console.Write("Podaj nazwę pliku pod którycm chcesz zapisać plik: ")
Dim nazwapliku As String = Console.ReadLine()
'zapisz plik
IO.File.WriteAllBytes("C:\Users\piotr\Desktop\" + nazwapliku, nowyplik)
Console.WriteLine("Bajty zostały odzyskane. Zapisano plik: " + "C:\Users\piotr\Desktop\" + nazwapliku)
Console.ReadLine()
End If
End If
End Sub
End Module
Zasada działania jest taka sama jak przy dodawaniu nagłówka JUNK, w tym wypadku pobieramy bajty pliku i modyfikujemy obszary, aby następnie dodać dwa bajty wielkości tekstu/pliku i jego bajty. Wiemy już gdzie ukryć dane w strukturze pliku. Zajmijmy się samym dźwiękiem. Jak już wcześniej wspomniałem pliki w formacie WAVE, zawierają dane 8, 16, 24, lub 32 bitowe. Gdzie 8 bitowych plików WAVE już się nie używa. Zmiana dźwięku poprzez zerowanie LSB będzie najbardziej efektywna, gdy będziemy mieli do czynienia z plikami 32 bitowymi, ponieważ ich modyfikacje nie zmienią znacząco dźwięku, gdyż jego długość jest dosyć duża:
16 bit = 00 00 do FF FF (0 do 65535)
24 bit = 00 00 00 do FF FF FF (0 do 16777215)
32 bity = 00 00 00 00 do FF FF FF FF (0 do 4294967295)
Zapożyczenie, nawet 2 bajtów w przypadku pliku 32 bitowego, nie pogorszy znacząco jego jakości. Przygotowałem aplikację, która prezentuje zmianę dźwięk po wyzerowaniu wskazanej ilości bajtów: program zerujący bity w pliku WAV
Uwaga, program może mieć problem z rysowaniem histogramu dla 32 bitowych plików WAV. Spowodowane jest to dużą skalą, która może w takim pliku występować. Histogram rysowany przez program jest tylko pomocniczy, aby w pełni zaobserwować zmiany dokonane na pliku, zapisz jego zmodyfikowaną wersje przy użyciu przycisku „Zapisz”.
Imports System.Windows.forms
Imports System.Drawing
Module Module1
Dim pictureboxKontener As New PictureBox
Dim buttonKontenera As New Button
Dim label1 As New Label
Dim trackbar1 As New TrackBar
Dim pictureboxGenerowany As New PictureBox
Dim buttonGeneratora As New Button
Dim buttonZapisz As New Button
Dim panel1 As New Panel
Dim panel2 As New Panel
Dim bajtyNaglowka As New List(Of Byte)
Dim DaneOryginalne As New List(Of UInteger)
Dim DaneLSB As New List(Of UInteger)
Dim najwyzszaWartoscDzwieku As Integer = 0
Dim iloscBitow As Short
Private Sub WygenerujForme()
Dim form1 As New Form
form1.StartPosition = FormStartPosition.CenterScreen
form1.Size = New System.Drawing.Size(371, 698)
panel1.Size = New System.Drawing.Size(355, 240)
panel1.Location = New System.Drawing.Point(0, 0)
panel1.AutoScroll = True
panel1.Anchor = AnchorStyles.Left Or AnchorStyles.Top Or AnchorStyles.Right
form1.Controls.Add(panel1)
buttonKontenera.Location = New System.Drawing.Point(5, 246)
buttonKontenera.Name = "buttonKontenera"
buttonKontenera.Size = New System.Drawing.Size(75, 23)
buttonKontenera.TabIndex = 1
buttonKontenera.Text = "Play"
AddHandler buttonKontenera.Click, AddressOf GrajOryginal
form1.Controls.Add(buttonKontenera)
label1.Location = New System.Drawing.Point(12, 287)
label1.Name = "label1"
label1.AutoSize = False
label1.Size = New System.Drawing.Size(331, 23)
label1.TabIndex = 2
label1.Text = "Wyzerowano 0 ostatnich bitów , to daje: 0 wojnych Bajtów."
form1.Controls.Add(label1)
trackbar1.Location = New System.Drawing.Point(0, 316)
trackbar1.Name = "trackbar1"
trackbar1.RightToLeft = RightToLeft.Yes
trackbar1.Size = New System.Drawing.Size(355, 45)
If iloscBitow = 16 Then
trackbar1.Maximum = 14
ElseIf iloscBitow = 24 Then
trackbar1.Maximum = 22
ElseIf iloscBitow = 32 Then
trackbar1.Maximum = 30
End If
trackbar1.TabIndex = 3
AddHandler trackbar1.ValueChanged, AddressOf TrackBar1_ZmianaWartosci
form1.Controls.Add(trackbar1)
panel2.Size = New System.Drawing.Size(355, 240)
panel2.Location = New System.Drawing.Point(0, 367)
panel2.AutoScroll = True
panel2.Anchor = AnchorStyles.Left Or AnchorStyles.Top Or AnchorStyles.Right
form1.Controls.Add(panel2)
buttonGeneratora.Location = New System.Drawing.Point(5, 626)
buttonGeneratora.Name = "buttonGeneratora"
buttonGeneratora.Size = New System.Drawing.Size(75, 23)
buttonGeneratora.TabIndex = 5
buttonGeneratora.Text = "Play"
AddHandler buttonGeneratora.Click, AddressOf GrajWygenerownyDzwiek
form1.Controls.Add(buttonGeneratora)
buttonZapisz.Location = New System.Drawing.Point(85, 626)
buttonZapisz.Name = "buttonZapisz"
buttonZapisz.Size = New System.Drawing.Size(75, 23)
buttonZapisz.TabIndex = 6
buttonZapisz.Text = "Zapisz"
AddHandler buttonZapisz.Click, AddressOf ZapiszKlik
form1.Controls.Add(buttonZapisz)
form1.ShowDialog()
End Sub
Sub Main()
Dim open_dialog As New OpenFileDialog()
open_dialog.InitialDirectory = "c:\"
open_dialog.Filter = "Image Files (*.wav)|*.wav"
open_dialog.Title = "Wskaż plik dźwiękowy"
If open_dialog.ShowDialog() = System.Windows.Forms.DialogResult.OK Then
PobierzBajty(open_dialog.FileName)
WygenerujForme()
End If
End Sub
Private Sub PobierzBajty(ByVal FileName As String)
Dim wavefile() As Byte = IO.File.ReadAllBytes(FileName)
Dim memstream As New IO.MemoryStream(wavefile)
Using binreader As New IO.BinaryReader(memstream)
bajtyNaglowka.AddRange(binreader.ReadBytes(4)) ' ChunkID
bajtyNaglowka.AddRange(binreader.ReadBytes(4)) ' filesize
bajtyNaglowka.AddRange(binreader.ReadBytes(4)) ' rifftype
' fmtID (czasem w plikach Wave znajduje się dodatkowy nagłówek zwany JUNK, jeśli istnieje, należy jego dane dodać lub usunąć)
'dodawanie
Do Until BitConverter.ToString({bajtyNaglowka(bajtyNaglowka.Count - 4), bajtyNaglowka(bajtyNaglowka.Count - 3),
bajtyNaglowka(bajtyNaglowka.Count - 2), bajtyNaglowka(bajtyNaglowka.Count - 1)}, 0) = "66-6D-74-20"
bajtyNaglowka.Add(binreader.ReadByte)
Loop
bajtyNaglowka.AddRange(binreader.ReadBytes(4)) ' fmtsize
Dim fmtsize As Byte() = {bajtyNaglowka(bajtyNaglowka.Count - 4), bajtyNaglowka(bajtyNaglowka.Count - 3),
bajtyNaglowka(bajtyNaglowka.Count - 2), bajtyNaglowka(bajtyNaglowka.Count - 1)}
bajtyNaglowka.AddRange(binreader.ReadBytes(2)) ' fmtcode
bajtyNaglowka.AddRange(binreader.ReadBytes(2)) ' fmtcode
bajtyNaglowka.AddRange(binreader.ReadBytes(4)) ' samplerate
bajtyNaglowka.AddRange(binreader.ReadBytes(4)) ' fmtAvgBPS
bajtyNaglowka.AddRange(binreader.ReadBytes(2)) ' fmtblockalign
bajtyNaglowka.AddRange(binreader.ReadBytes(2)) ' bitdepth
iloscBitow = BitConverter.ToInt16({bajtyNaglowka(bajtyNaglowka.Count - 2), bajtyNaglowka(bajtyNaglowka.Count - 1)}, 0)
If BitConverter.ToUInt32(fmtsize, 0) = 18 Then
bajtyNaglowka.AddRange(binreader.ReadBytes(2))
End If
' DataID'
Do Until BitConverter.ToString({bajtyNaglowka(bajtyNaglowka.Count - 4), bajtyNaglowka(bajtyNaglowka.Count - 3),
bajtyNaglowka(bajtyNaglowka.Count - 2), bajtyNaglowka(bajtyNaglowka.Count - 1)}, 0) = "64-61-74-61"
bajtyNaglowka.Add(binreader.ReadByte)
Loop
bajtyNaglowka.AddRange(binreader.ReadBytes(4)) ' DataSize
Dim DataSize As Byte() = {bajtyNaglowka(bajtyNaglowka.Count - 4), bajtyNaglowka(bajtyNaglowka.Count - 3) _
, bajtyNaglowka(bajtyNaglowka.Count - 2), bajtyNaglowka(bajtyNaglowka.Count - 1)}
'ładuje odpowiednio duże dane do listy
If iloscBitow = 16 Then
For i = 0 To (BitConverter.ToUInt32(DataSize, 0) / 2) - 1
DaneOryginalne.Add(binreader.ReadUInt16())
Next
ElseIf iloscBitow = 32 Then
For i = 0 To (BitConverter.ToUInt32(DataSize, 0) / 4) - 1
DaneOryginalne.Add(binreader.ReadUInt32())
Next
ElseIf iloscBitow = 24 Then
For i = 0 To (BitConverter.ToUInt32(DataSize, 0) / 3) - 1
Dim DataSize2(3) As Byte
DataSize2(3) = 0
DataSize2(0) = binreader.ReadByte
DataSize2(1) = binreader.ReadByte
DataSize2(2) = binreader.ReadByte
DaneOryginalne.Add(BitConverter.ToUInt32(DataSize2, 0))
Next
End If
End Using
OryginalHistogram()
End Sub
Private Sub OryginalHistogram()
Dim przeskok As Integer
pictureboxKontener.BorderStyle = System.Windows.Forms.BorderStyle.FixedSingle
pictureboxKontener.Location = New System.Drawing.Point(0, 0)
pictureboxKontener.Name = "Kontener"
If Not iloscBitow = 32 Then
pictureboxKontener.Size = New System.Drawing.Size((DaneOryginalne.Count - 1) / 2, 220)
przeskok = 1
Else
pictureboxKontener.Size = New System.Drawing.Size((DaneOryginalne.Count - 1) / 2000, 220)
przeskok = (DaneOryginalne.Count - 1) / 2000
End If
pictureboxKontener.TabIndex = 0
pictureboxKontener.TabStop = False
panel1.Controls.Add(pictureboxKontener)
Dim obraz As New Bitmap(pictureboxKontener.Width, 240)
Dim gfx As Graphics = Graphics.FromImage(obraz)
'Stwórz grafikę kwadratu ktory posłuży za tło
gfx.FillRectangle(Brushes.White, 0, 0, obraz.Width, obraz.Height)
'ustawiamy przeskok tak aby zmieściły nam się dane (2*szerokość obrazka)
Dim polowa As Integer = (obraz.Height / 2) 'ustalamy połowe wysokości obrazka
If Not iloscBitow = 32 Then
For i = 1 To obraz.Width - 10
If DaneOryginalne(i * przeskok) > najwyzszaWartoscDzwieku Then 'wymagane do stworzenia histogramu
najwyzszaWartoscDzwieku = DaneOryginalne(i * przeskok)
End If
Next
Else
For i = 1 To obraz.Width - 10
If DaneOryginalne(i * przeskok) > najwyzszaWartoscDzwieku Then 'wymagane do stworzenia histogramu
If DaneOryginalne(i * przeskok) > Integer.MaxValue Then
najwyzszaWartoscDzwieku = Integer.MaxValue / 4
Exit For
Else
najwyzszaWartoscDzwieku = DaneOryginalne(i * przeskok)
End If
End If
Next
End If
For i As UInteger = 1 To obraz.Width - 10 Step 2 'ponieważ w jednym ruchu rysujemy dwie linie
Dim leftdata As UInteger = Math.Abs(DaneOryginalne(i * przeskok)) 'podejmujemy (i* przeskok) element
'procent jaki osiąga dzwięk w stosunku do najdłuższego znalezionego dźwięku
Dim leftpercent As Double = leftdata / (najwyzszaWartoscDzwieku * 2)
'otrzymujemy procent połowy wysokości obrazka odpowiadającej długości dźwięku
Dim leftpicheight As Integer = leftpercent * obraz.Height
gfx.DrawLine(Pens.Green, i, polowa, i, leftpicheight + polowa) 'generuje grafikę słupka w górę
'podejmujemy ((i+1)* przeskok) element (i+1 ponieważ mamy "step 2" w pętli
Dim rightdata As UInteger = Math.Abs(DaneOryginalne((i + 1) * przeskok))
Dim rightpercent As Double = -rightdata / (najwyzszaWartoscDzwieku * 2) 'rysuje słupek w dół
Dim rightpicheight As Integer = rightpercent * obraz.Height
gfx.DrawLine(Pens.Black, i, polowa, i, rightpicheight + polowa) 'generuje grafikę słupka w dół
Next
pictureboxKontener.Image = obraz
End Sub
Private Sub GrajOryginal()
My.Computer.Audio.Stop()
Dim oryginal As Byte()
Dim listaPolaczona As New List(Of Byte)
listaPolaczona.AddRange(bajtyNaglowka)
If iloscBitow = 16 Then
For i As Integer = 0 To DaneOryginalne.Count - 1
Dim test As Byte() = BitConverter.GetBytes(DaneOryginalne(i))
listaPolaczona.Add(test(0))
listaPolaczona.Add(test(1))
Next
ElseIf iloscBitow = 32 Then
For i As Integer = 0 To DaneOryginalne.Count - 1
Dim test As Byte() = BitConverter.GetBytes(DaneOryginalne(i))
listaPolaczona.Add(test(0))
listaPolaczona.Add(test(1))
listaPolaczona.Add(test(2))
listaPolaczona.Add(test(3))
Next
ElseIf iloscBitow = 24 Then
For i As Integer = 0 To DaneOryginalne.Count - 1
Dim test As Byte() = BitConverter.GetBytes(DaneOryginalne(i))
listaPolaczona.Add(test(0))
listaPolaczona.Add(test(1))
listaPolaczona.Add(test(2))
Next
End If
oryginal = listaPolaczona.ToArray()
My.Computer.Audio.Play(oryginal, AudioPlayMode.Background)
End Sub
Dim LISTA As New List(Of String)
Private Sub TrackBar1_ZmianaWartosci()
DaneLSB.Clear()
LISTA.Clear()
For i As UInteger = 0 To DaneOryginalne.Count - 1
Dim wartosc As UInteger = DaneOryginalne(i) - (DaneOryginalne(i) Mod (2 ^ trackbar1.Value))
Dim test As Byte() = BitConverter.GetBytes(DaneOryginalne(i))
Dim test2 As Byte() = BitConverter.GetBytes(wartosc)
Dim string1 As String = BitConverter.ToString(test).ToString
Dim testOdwrocony As String() = string1.Split("-")
Dim dolisty1 As String = testOdwrocony(3) + "-" + testOdwrocony(2) + "-" + testOdwrocony(1) + "-" + testOdwrocony(0)
Dim string2 As String = BitConverter.ToString(test2).ToString
Dim testOdwrocony2 As String() = string2.Split("-")
Dim dolisty2 As String = testOdwrocony2(3) + "-" + testOdwrocony2(2) + "-" + testOdwrocony2(1) + "-" + testOdwrocony2(0)
Dim test3 As UInteger = DaneOryginalne(i) Mod (2 ^ trackbar1.Value)
LISTA.Add(DaneOryginalne(i).ToString + " (" + dolisty1 + ") -" + test3.ToString +
" =" + (DaneOryginalne(i) - test3).ToString + " (" + dolisty2 + ")" + " (" +
Convert.ToString(test2(3), 2).PadLeft(8, "0") + "-" + Convert.ToString(test2(2), 2).PadLeft(8, "0") _
+ "-" + Convert.ToString(test2(1), 2).PadLeft(8, "0") + "-" + Convert.ToString(test2(0), 2).PadLeft(8, "0") + ")")
DaneLSB.Add(DaneOryginalne(i) - (DaneOryginalne(i) Mod (2 ^ trackbar1.Value)))
Next
label1.Text = "Wyzerowano " + trackbar1.Value.ToString + " ostatnich bitów, to daje: " +
(Math.Floor((DaneOryginalne.Count / 8) * trackbar1.Value).ToString + " wojnych Bajtów.")
GenerowanyHistogram()
End Sub
Private Sub GenerowanyHistogram()
panel2.Controls.Clear()
Dim przeskok As Integer
pictureboxGenerowany.BorderStyle = System.Windows.Forms.BorderStyle.FixedSingle
pictureboxGenerowany.Location = New System.Drawing.Point(0, 0)
pictureboxGenerowany.Name = "pictureboxGenerowany"
If Not iloscBitow = 32 Then
pictureboxGenerowany.Size = New System.Drawing.Size((DaneOryginalne.Count - 1) / 2, 220)
przeskok = 1
Else
pictureboxGenerowany.Size = New System.Drawing.Size((DaneOryginalne.Count - 1) / 2000, 220)
przeskok = (DaneOryginalne.Count - 1) / 2000
End If
pictureboxGenerowany.TabIndex = 4
pictureboxGenerowany.TabStop = False
panel2.Controls.Add(pictureboxGenerowany)
Dim obraz As New Bitmap(pictureboxGenerowany.Width, 240)
Dim gfx As Graphics = Graphics.FromImage(obraz)
'Stwórz grafikę kwadratu ktory posłuży za tło
gfx.FillRectangle(Brushes.White, 0, 0, obraz.Width, obraz.Height)
Dim polowa As Integer = (obraz.Height / 2)
For i As UInteger = 1 To obraz.Width - 10 Step 2 'ponieważ w jednym ruchu rysujemy dwie linie
Dim leftdata As UInteger = Math.Abs(DaneLSB(i * przeskok))
Dim leftpercent As Single = leftdata / (najwyzszaWartoscDzwieku * 2)
Dim leftpicheight As Integer = leftpercent * obraz.Height
gfx.DrawLine(Pens.Green, i, polowa, i, leftpicheight + polowa)
Dim rightdata As UInteger = Math.Abs(DaneLSB((i + 1) * przeskok))
Dim rightpercent As Single = -rightdata / (najwyzszaWartoscDzwieku * 2)
Dim rightpicheight As Integer = rightpercent * obraz.Height
gfx.DrawLine(Pens.Black, i, polowa, i, rightpicheight + polowa)
Next
pictureboxGenerowany.Image = obraz
End Sub
Private Sub GrajWygenerownyDzwiek()
My.Computer.Audio.Stop()
Dim Wygenerowany As Byte()
Dim listaPolaczona As New List(Of Byte)
listaPolaczona.AddRange(bajtyNaglowka)
If iloscBitow = 16 Then
For i As Integer = 0 To DaneLSB.Count - 1
Dim test As Byte() = BitConverter.GetBytes(DaneLSB(i))
listaPolaczona.Add(test(0))
listaPolaczona.Add(test(1))
Next
ElseIf iloscBitow = 32 Then
For i As Integer = 0 To DaneLSB.Count - 1
Dim test As Byte() = BitConverter.GetBytes(DaneLSB(i))
listaPolaczona.Add(test(0))
listaPolaczona.Add(test(1))
listaPolaczona.Add(test(2))
listaPolaczona.Add(test(3))
Next
ElseIf iloscBitow = 24 Then
For i As Integer = 0 To DaneLSB.Count - 1
Dim test As Byte() = BitConverter.GetBytes(DaneLSB(i))
listaPolaczona.Add(test(0))
listaPolaczona.Add(test(1))
listaPolaczona.Add(test(2))
Next
End If
Wygenerowany = listaPolaczona.ToArray()
My.Computer.Audio.Play(Wygenerowany, AudioPlayMode.Background)
End Sub
Private Sub ZapiszKlik()
Dim Wygenerowany As Byte()
Dim listaPolaczona As List(Of Byte) = bajtyNaglowka
If iloscBitow = 16 Then
For i As Integer = 0 To DaneLSB.Count - 1
Dim test As Byte() = BitConverter.GetBytes(DaneLSB(i))
listaPolaczona.Add(test(0))
listaPolaczona.Add(test(1))
Next
ElseIf iloscBitow = 32 Then
For i As Integer = 0 To DaneLSB.Count - 1
Dim test As Byte() = BitConverter.GetBytes(DaneLSB(i))
listaPolaczona.Add(test(0))
listaPolaczona.Add(test(1))
listaPolaczona.Add(test(2))
listaPolaczona.Add(test(3))
Next
ElseIf iloscBitow = 24 Then
For i As Integer = 0 To DaneLSB.Count - 1
Dim test As Byte() = BitConverter.GetBytes(DaneLSB(i))
listaPolaczona.Add(test(0))
listaPolaczona.Add(test(1))
listaPolaczona.Add(test(2))
Next
End If
Wygenerowany = listaPolaczona.ToArray()
Dim saveFileDialog1 As New SaveFileDialog()
saveFileDialog1.Title = "Save an wav File"
saveFileDialog1.Filter = "Wav Files | *.wav"
saveFileDialog1.DefaultExt = "wav"
saveFileDialog1.ShowDialog()
If saveFileDialog1.FileName <> "" Then
IO.File.WriteAllBytes(saveFileDialog1.FileName, Wygenerowany)
Dim sciezka As String = IO.Path.GetDirectoryName(saveFileDialog1.FileName) _
+ "\" + IO.Path.GetFileNameWithoutExtension(saveFileDialog1.FileName)
IO.File.WriteAllLines(sciezka + "_listabitow.txt", LISTA)
End If
End Sub
End Module
Aplikacja jest dosyć rozbudowana, ale jej działanie jest bardzo proste. Pobiera bajty pliku i segreguje je, umieszczając w odpowiednich listach, aby po modyfikacji można było połączyć je w całość i odtworzyć (wyświetlić histogram). Pliki, na których ja testowałem algorytmy::
Jeśli wyzerujemy ostatnie 8 bitów w 16 bitowym pliku WAVE, zmiana będzie niezauważalna (w dźwięku). Dopiero wyzerowanie więcej niż 10 bitów zmienia zauważalnie jakość dźwięku:
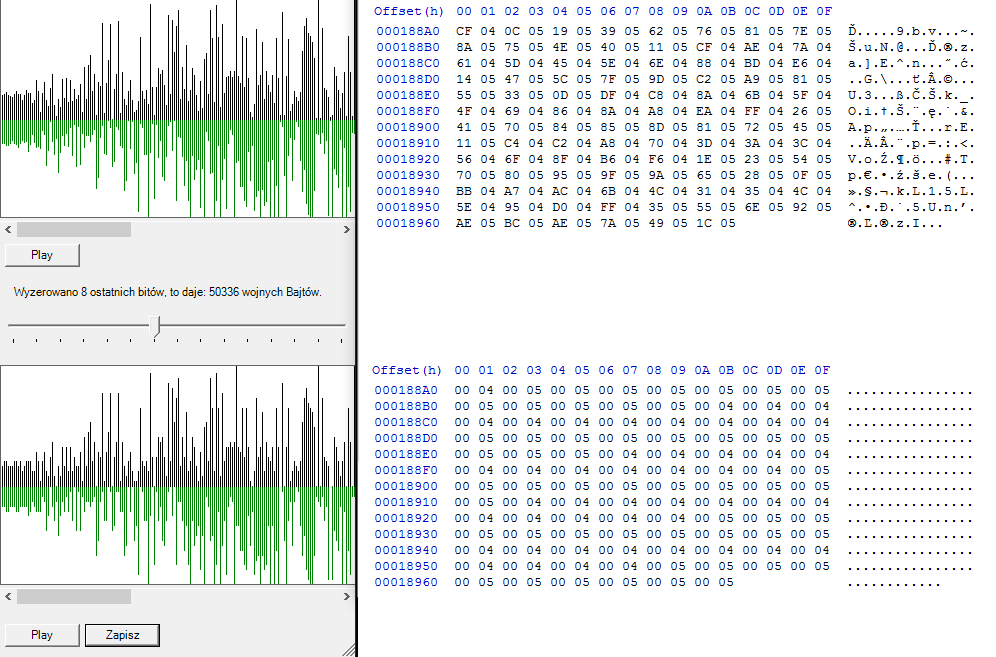
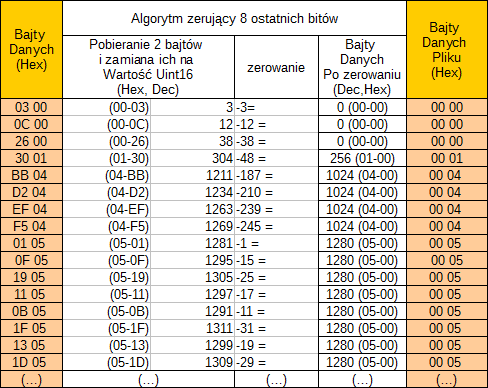
Procedura zerowania 8 bitów dla 16-bitowego pliku WAVe wygląda następująco:
DaneOryginalne(i) - (DaneOryginalne(i) Mod (2 ^ trackbar1.Value)) 'w naszym wypadku trackbar1.Value =8
Odpowiednio, dla pliku 16, 24, 32 bitowego( do pobrania na początku artykułu) zerowanie przebiega następująco:
ZerowanieOstatniegoBajtaW16bitowejPróbce –> plik audio po zerowaniu ostatniego bajta: ZerowanieOstatniegoBajtaW16bitowejPróbce
ZerowanieOstatniegoBajtaW24bitowejPróbce –> plik audio po zerowaniu ostatniego bajta: ZerowanieOstatniegoBajtaW24bitowejPróbce
ZerowanieOstatniegoBajtaW32bitowejPróbce –> plik audio po zerowaniu ostatniego bajta: ZerowanieOstatniegoBajtaW32bitowejPróbce
Zachęcam was do przeprowadzenia takiego eksperymentu, przy użyciu algorytmu i sprawdzenia ich na własnych uszach. Ukrycie pliku w takim nośniku nie powinno sprawić wam problemu. Tak jak w przypadku plików graficznych w formacie bmp, zerujemy bity pliku dźwiękowego (kontener) i ukrywamy tam bity naszego pliku. Aby, nie zerować wszystkich bitów danych pliku WAV użyjemy czterech pierwszych bajtów danych do zapisania w nich wielkości pliku, warto również użyć formatu danych Uinteger(dlaczego, dowiesz się, rozwijając zakładkę projektu). Będzie to wyglądało następująco:
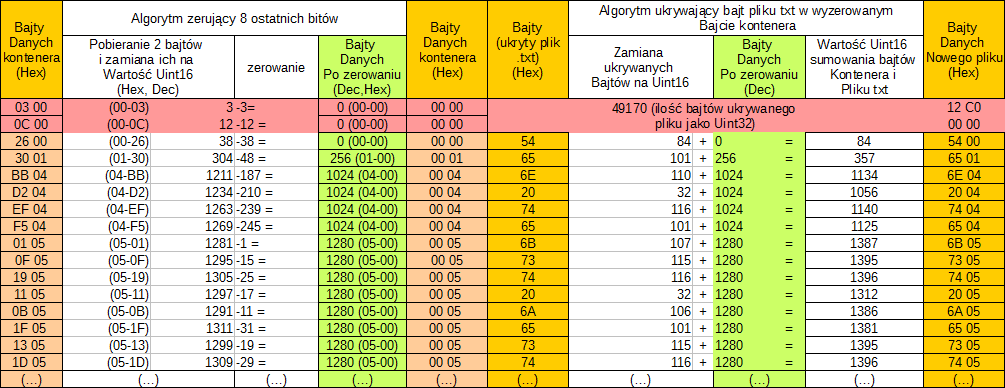
Plik WAVE 16-bitowy z ukrytym tekstem (ukryty plik) :
Jeśli już rozbieraliście na części plik WAV, na pewno zauważyliście, że danych dźwiękowych jest bardzo dużo, więc z plik ukrywany może być znacząco mniejszy niż ilość danych dźwiękowych. Toteż ukrywanie wszystkich bajtów pliku tajnego na początku danych kontenera może spowodować słyszalny szum, dużo lepszą metodą jest podzielenie ilości dostępnych bajtów przez ilość bajtów pliku tajnego i zapisanie jego bajtów, w co piątym, szóstym czy siódmym elemencie:
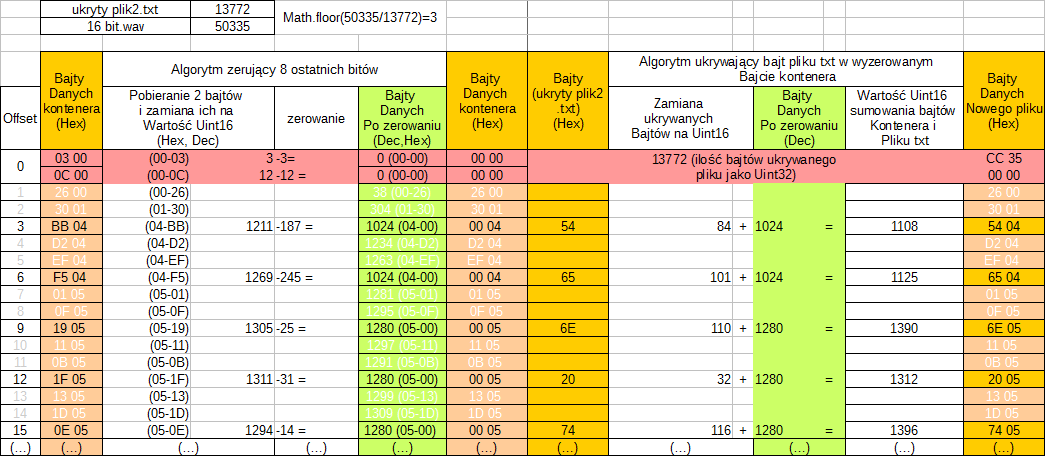
Znając ilość ukrytych danych (pierwsze cztery bajty danych kontenera) bajty można rozłożyć w kontenerze tak jak na obrazku powyrzej.
plik ukryty w kontenerze: ukryty plik2
do odsłuchania, plik z ukrytymi danymi (16-bit wave z ukrytym plikiem „ukryty plik2”):
Przykładowy algorytm ukrywający bajty pliku w kontenerze WAV:
Już na wstępie chciałbym zaznaczyć, że utworzenie programu do szyfrowania bajtów pliku dźwiękowego będzie trochę trudniejsze niż w przypadku plików graficznych. Problem może sprawić to, że operujemy na więcej niż jednym bajcie. Program pobiera dwa, trzy lub cztery bajty i zamienia je na Uint (zakres integer jest od -2147483648 do 2147483647 (7F-FF-FF-FF) a Uint od 0 do 4294967295 (FF-FF-FF-FF)), jak łatwo się domyślić cztery bajty przyjmują zakres od 00-00-00-00 do FF-FF-FF-FF, a więc wszelkiego rodzaju zamiana czterech czy dwóch bajtów na liczbę naturalną będzie wygodniejsza dla Uint. Jeśli wartość bajtów przekroczy maksymalną wartość integer, wtedy liczna naturalna przyjmuje wartość ujemną, a dodawanie czy odejmowanie ich wartości nie będzie miało sensu. Program poniżej przeprowadza edycje bajtów pliku WAV, wyodrębnia z niego poszczególne elementy i je modyfikuje:
Z uwagi na to, że nie ma w vb.net czegoś takiego jak Uint24, pobieramy trzy bajty i dodajemy zerowy bajt z przodu i zamieniamy cztery bajty na Uint32
Imports System.Windows.Forms
Module Module1
Sub Main()
Dim open_dialog As New OpenFileDialog()
Dim open_dialog_ukrywany As New OpenFileDialog()
open_dialog.InitialDirectory = "c:\"
open_dialog.Filter = "Image Files (*.wav)| *.wav"
open_dialog.Title = "Wskarz kontener w formacie WAV w którym ukryjesz plik"
If open_dialog.ShowDialog() = System.Windows.Forms.DialogResult.OK Then
open_dialog_ukrywany.InitialDirectory = "c:\"
open_dialog_ukrywany.Filter = "All Files|*.*"
open_dialog_ukrywany.Title = "Wybierz plik który chcesz ukryć"
If open_dialog_ukrywany.ShowDialog() = System.Windows.Forms.DialogResult.OK Then
Dim adresKontenera As String = open_dialog.FileName
Dim adreskUkrywany As String = open_dialog_ukrywany.FileName
Dim DaneOryginalne As New List(Of UInteger)
Dim iloscBitow As Integer = 0
Dim bajtyNaglowka As New List(Of Byte)
Dim plikUkrywany() As Byte = IO.File.ReadAllBytes(adreskUkrywany)
Dim wavefile() As Byte = IO.File.ReadAllBytes(adresKontenera)
Dim memstream As New IO.MemoryStream(wavefile)
'''''obszar oddziela nagłówek od danych
Using binreader As New IO.BinaryReader(memstream)
' DataID'
bajtyNaglowka.AddRange(binreader.ReadBytes(4)) ' ChunkID
Do Until BitConverter.ToString({bajtyNaglowka(bajtyNaglowka.Count - 4),
bajtyNaglowka(bajtyNaglowka.Count - 3), bajtyNaglowka(bajtyNaglowka.Count - 2),
bajtyNaglowka(bajtyNaglowka.Count - 1)}, 0) = "66-6D-74-20"
bajtyNaglowka.Add(binreader.ReadByte)
Loop
bajtyNaglowka.AddRange(binreader.ReadBytes(4)) ' fmtsize
Dim fmtsize As Byte() = {bajtyNaglowka(bajtyNaglowka.Count - 4),
bajtyNaglowka(bajtyNaglowka.Count - 3), bajtyNaglowka(bajtyNaglowka.Count - 2),
bajtyNaglowka(bajtyNaglowka.Count - 1)}
bajtyNaglowka.AddRange(binreader.ReadBytes(14)) ' fmtcode
bajtyNaglowka.AddRange(binreader.ReadBytes(2)) ' bitdepth
iloscBitow = BitConverter.ToInt16({bajtyNaglowka(bajtyNaglowka.Count - 2),
bajtyNaglowka(bajtyNaglowka.Count - 1)}, 0)
If BitConverter.ToInt32(fmtsize, 0) = 18 Then
bajtyNaglowka.AddRange(binreader.ReadBytes(2))
End If
' DataID'
Do Until BitConverter.ToString({bajtyNaglowka(bajtyNaglowka.Count - 4),
bajtyNaglowka(bajtyNaglowka.Count - 3), bajtyNaglowka(bajtyNaglowka.Count - 2),
bajtyNaglowka(bajtyNaglowka.Count - 1)}, 0) = "64-61-74-61"
bajtyNaglowka.Add(binreader.ReadByte)
Loop
bajtyNaglowka.AddRange(binreader.ReadBytes(4)) ' DataSize
Dim DataSize As Byte() = {bajtyNaglowka(bajtyNaglowka.Count - 4),
bajtyNaglowka(bajtyNaglowka.Count - 3), bajtyNaglowka(bajtyNaglowka.Count - 2),
bajtyNaglowka(bajtyNaglowka.Count - 1)}
'ładuje odpowiednio duże dane do listy
If iloscBitow = 16 Then
For i = 0 To (BitConverter.ToUInt32(DataSize, 0) / 2) - 1
DaneOryginalne.Add(binreader.ReadUInt16())
Next
ElseIf iloscBitow = 32 Then
For i = 0 To (BitConverter.ToUInt32(DataSize, 0) / 4) - 1
DaneOryginalne.Add(binreader.ReadUInt32())
Next
ElseIf iloscBitow = 24 Then
For i = 0 To (BitConverter.ToUInt32(DataSize, 0) / 3) - 1
Dim DataSize2(3) As Byte
DataSize2(3) = 0
DataSize2(0) = binreader.ReadByte
DataSize2(1) = binreader.ReadByte
DataSize2(2) = binreader.ReadByte
DaneOryginalne.Add(BitConverter.ToUInt32(DataSize2, 0))
Next
End If
End Using
'''''
'sparwdza czy plik ukrywany ma mniej danych niż kontener
If Not plikUkrywany.Length + 2 > DaneOryginalne.Count Then
Dim przeskok As UInteger = 1
Dim listaPolaczona As List(Of Byte) = bajtyNaglowka
Dim wielkoscpliku As UInteger = plikUkrywany.Length
If iloscBitow = 16 Then
'dodaje bajty wielkości pliku
listaPolaczona.Add(BitConverter.GetBytes(wielkoscpliku)(0))
listaPolaczona.Add(BitConverter.GetBytes(wielkoscpliku)(1))
listaPolaczona.Add(BitConverter.GetBytes(wielkoscpliku)(2))
listaPolaczona.Add(BitConverter.GetBytes(wielkoscpliku)(3))
DaneOryginalne.RemoveAt(0) 'usuwa pierwszy wiersz (ułatwia to pracę algorytmu)
przeskok = Math.Floor(((DaneOryginalne.Count - 1) / plikUkrywany.Length))
'algorytm ukrywający bajty
For i As UInteger = 0 To plikUkrywany.Length - 1
DaneOryginalne((i + 1) * przeskok) = (DaneOryginalne((i + 1) * przeskok) -
(DaneOryginalne((i + 1) * przeskok) Mod (2 ^ 8))) + Convert.ToInt32(plikUkrywany(i))
Next
Else
przeskok = Math.Floor(((DaneOryginalne.Count - 1) / plikUkrywany.Length))
'algorytm ukrywający bajty
For i As UInteger = 0 To plikUkrywany.Length - 1
DaneOryginalne((i + 1) * przeskok) = (DaneOryginalne((i + 1) * przeskok) -
(DaneOryginalne((i + 1) * przeskok) Mod (2 ^ 8))) + Convert.ToInt32(plikUkrywany(i))
Next
End If
Dim Wygenerowany As Byte()
'zespalanie pliku
If iloscBitow = 16 Then
For i As UInteger = 1 To DaneOryginalne.Count - 1
Dim test As Byte() = BitConverter.GetBytes(DaneOryginalne(i))
listaPolaczona.Add(test(0))
listaPolaczona.Add(test(1))
Next
ElseIf iloscBitow = 32 Then
'dodaje bajty wielkości pliku
listaPolaczona.Add(BitConverter.GetBytes(wielkoscpliku)(0))
listaPolaczona.Add(BitConverter.GetBytes(wielkoscpliku)(1))
listaPolaczona.Add(BitConverter.GetBytes(wielkoscpliku)(2))
listaPolaczona.Add(BitConverter.GetBytes(wielkoscpliku)(3))
For i As UInteger = 1 To DaneOryginalne.Count - 1
Dim test As Byte() = BitConverter.GetBytes(DaneOryginalne(i))
listaPolaczona.AddRange(test.ToList)
Next
ElseIf iloscBitow = 24 Then
'dodaje bajty wielkości pliku
listaPolaczona.Add(BitConverter.GetBytes(wielkoscpliku)(0))
listaPolaczona.Add(BitConverter.GetBytes(wielkoscpliku)(1))
listaPolaczona.Add(BitConverter.GetBytes(wielkoscpliku)(2))
For i As UInteger = 1 To DaneOryginalne.Count - 1
Dim test As Byte() = BitConverter.GetBytes(DaneOryginalne(i))
listaPolaczona.Add(test(0))
listaPolaczona.Add(test(1))
listaPolaczona.Add(test(2))
Next
End If
Wygenerowany = listaPolaczona.ToArray()
Console.WriteLine()
Console.Write("Podaj nazwę nowego pliku: ")
Dim nazwapliku As String = Console.ReadLine()
'zapisz plik
IO.File.WriteAllBytes("C:\Users\piotr\Desktop\" + nazwapliku + ".wav", Wygenerowany)
Console.WriteLine("Bajty zostały ukryte. Zapisano plik: " +
"C:\Users\piotr\Desktop\" + nazwapliku)
Console.ReadLine()
Else
Console.WriteLine("Twój kontener jest zbyt mały.")
Console.WriteLine("Bajty kontenera: " + DaneOryginalne.Count.ToString)
Console.WriteLine("Bajty pliku ukrywanego: " + plikUkrywany.Length.ToString)
Console.WriteLine("Wybierz większy plik kontenera.")
Console.ReadLine()
End If
End If
End If
End Sub
End Module
Jeśli wiemy jak dodawać bajty, ich wyciągnięcie nie stanowi problemu, z bajtów danych pobieramy informację na temat wielkości pliku i na tej podstawie wyodrębniamy bajty..
Imports System.Windows.Forms
Module Module1
Sub Main()
Dim open_dialog As New OpenFileDialog()
open_dialog.InitialDirectory = "c:\"
open_dialog.Filter = "Image Files (*.wav)| *.wav"
open_dialog.Title = "Wskarz kontener w formacie WAV w którym ukryjesz plik"
If open_dialog.ShowDialog() = System.Windows.Forms.DialogResult.OK Then
Dim adresKontenera As String = open_dialog.FileName
Dim DaneOryginalne As New List(Of Integer)
Dim iloscBitow As Integer = 0
Dim bajtyNaglowka As New List(Of Byte)
Dim wavefile() As Byte = IO.File.ReadAllBytes(adresKontenera)
Dim memstream As New IO.MemoryStream(wavefile)
Dim wielkoscpliku As Integer = 0
'Oddziela nagłówek od danych
Using binreader As New IO.BinaryReader(memstream)
' DataID'
bajtyNaglowka.AddRange(binreader.ReadBytes(4)) ' ChunkID
Do Until BitConverter.ToString({bajtyNaglowka(bajtyNaglowka.Count - 4),
bajtyNaglowka(bajtyNaglowka.Count - 3), bajtyNaglowka(bajtyNaglowka.Count - 2),
bajtyNaglowka(bajtyNaglowka.Count - 1)}, 0) = "66-6D-74-20"
bajtyNaglowka.Add(binreader.ReadByte)
Loop
bajtyNaglowka.AddRange(binreader.ReadBytes(4)) ' fmtsize
Dim fmtsize As Byte() = {bajtyNaglowka(bajtyNaglowka.Count - 4),
bajtyNaglowka(bajtyNaglowka.Count - 3), bajtyNaglowka(bajtyNaglowka.Count - 2),
bajtyNaglowka(bajtyNaglowka.Count - 1)}
bajtyNaglowka.AddRange(binreader.ReadBytes(14)) ' fmtcode
bajtyNaglowka.AddRange(binreader.ReadBytes(2)) ' bitdepth
iloscBitow = BitConverter.ToInt16({bajtyNaglowka(bajtyNaglowka.Count - 2),
bajtyNaglowka(bajtyNaglowka.Count - 1)}, 0)
If BitConverter.ToInt32(fmtsize, 0) = 18 Then
bajtyNaglowka.AddRange(binreader.ReadBytes(2))
End If
' DataID'
Do Until BitConverter.ToString({bajtyNaglowka(bajtyNaglowka.Count - 4),
bajtyNaglowka(bajtyNaglowka.Count - 3), bajtyNaglowka(bajtyNaglowka.Count - 2),
bajtyNaglowka(bajtyNaglowka.Count - 1)}, 0) = "64-61-74-61"
bajtyNaglowka.Add(binreader.ReadByte)
Loop
bajtyNaglowka.AddRange(binreader.ReadBytes(4)) ' DataSize
Dim DataSize As Byte() = {bajtyNaglowka(bajtyNaglowka.Count - 4),
bajtyNaglowka(bajtyNaglowka.Count - 3), bajtyNaglowka(bajtyNaglowka.Count - 2),
bajtyNaglowka(bajtyNaglowka.Count - 1)}
'ładuje odpowiednio duże dane do listy
If iloscBitow = 16 Then
DaneOryginalne.Add(binreader.ReadInt32())
For i = 2 To (BitConverter.ToInt32(DataSize, 0) / 2) - 1
DaneOryginalne.Add(binreader.ReadInt16())
Next
ElseIf iloscBitow = 32 Then
For i = 1 To (BitConverter.ToInt32(DataSize, 0) / 4) - 1
DaneOryginalne.Add(binreader.ReadInt32())
Next
ElseIf iloscBitow = 24 Then
For i = 1 To (BitConverter.ToInt32(DataSize, 0) / 3) - 1
Dim DataSize2(3) As Byte
DataSize2(3) = 0
DataSize2(0) = binreader.ReadByte
DataSize2(1) = binreader.ReadByte
DataSize2(2) = binreader.ReadByte
DaneOryginalne.Add(BitConverter.ToInt32(DataSize2, 0))
Next
End If
End Using
Dim przeskok As Integer = 1
Dim test2 As Byte() = BitConverter.GetBytes(DaneOryginalne(0))
wielkoscpliku = BitConverter.ToInt32(test2, 0)
If iloscBitow = 16 Then
przeskok = Math.Floor(((DaneOryginalne.Count - 1) / wielkoscpliku))
Else
przeskok = Math.Floor(((DaneOryginalne.Count - 1) / wielkoscpliku))
End If
'tworzymy nowy plik
Dim Wygenerowany As Byte()
Dim listaPolaczona As New List(Of Byte)
If iloscBitow = 16 Then
For i As Integer = 1 To wielkoscpliku
Dim test As Byte() = BitConverter.GetBytes(DaneOryginalne(i * przeskok))
listaPolaczona.Add(test(0))
Next
ElseIf iloscBitow = 32 Then
For i As Integer = 1 To wielkoscpliku
Dim test As Byte() = BitConverter.GetBytes(DaneOryginalne(i * przeskok))
listaPolaczona.Add(test(0))
Next
ElseIf iloscBitow = 24 Then
For i As Integer = 1 To wielkoscpliku
Dim test As Byte() = BitConverter.GetBytes(DaneOryginalne(i * przeskok))
listaPolaczona.Add(test(0))
Next
End If
Wygenerowany = listaPolaczona.ToArray()
Console.WriteLine()
Console.Write("Podaj nazwę pliku pod którycm chcesz go zapisać: ")
Dim nazwapliku As String = Console.ReadLine()
'zapisz plik
IO.File.WriteAllBytes("C:\Users\piotr\Desktop\" + nazwapliku, Wygenerowany)
Console.WriteLine("Bajty zostały odzyskane. Zapisano plik: " + "C:\Users\piotr\Desktop\" + nazwapliku)
Console.ReadLine()
End If
End Sub
End Module
Plik wygenerowany, nie będzie miał rozszerzenia. Spowodowane jest to brakiem informacji (którą jeśli chcemy, możemy umieścić w kontenerze) o rodzaju pliku. Warto również połączyć możliwości JUNK i LSB.
Do przetestowania: Program_ukrywający_bajty_w_pliku_wav , Odzyskiwanie_ostatniego_bajta_z_pliku_WAV
(artykuł będzie rozwijany)

