Kolejnym często wykorzystywanym współczynnikiem do określenia jakości modelu prognostycznego jest ,,Współczynnik Theila”. Współczynnik Theila służy do obliczenia całkowitego względnego błędu prognozy w okresie testowania. Wyraża się go wzorem:

Podobnie jak w przypadku RMSE. Im mniejsza wartość współczynnika, tym wyższa jakość modelu, wartość zerową otrzymujemy dla prognoz idealnie trafnych. Im wartość współczynnika Theila jest większa, tym wyższe są różnice między prognozami a wartościami zmiennej prognozowanej. Cechą szczególną współczynnika Theila jest możliwość jego rozkładu na sumę trzech składników, które pozwalają na ocenę źródła błędu predykcji.
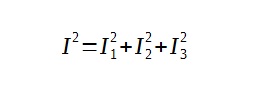
Gdzie poszczególne elementy wyrażamy wzorem:
1.)

Współczynnik ten odzwierciedla obciążenie predykcji, czyli to, w jakim stopniu nie udało się odgadnąć średniej wartości zmiennej prognozowanej.
2.)

Określa, w jakim stopniu zmienność prognozy i zmiennej prognozowanej są do siebie zbliżone. Składnik ten ma związek z precyzją prognozowania.
3.)
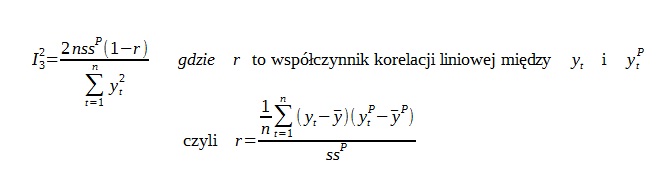
Składnik ten informuje czy wystąpiła zgodność kierunków zmian prognoz z rzeczywistym kierunkiem zmian prognozowanej. Nieodgadnięcie kierunku tendencji w szeregu świadczy o słabej przydatności modelu do odzwierciedlenia tych tendencji.
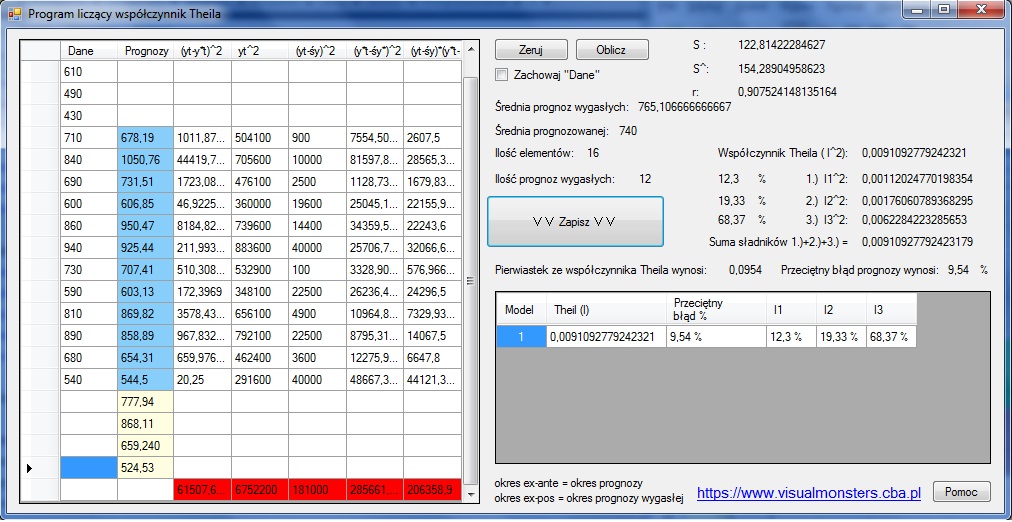
Podczas obliczania wybieramy zazwyczaj model o najwyższym zróżnicowaniu składników. Pokaże to na przykładzie. Wykorzystałem program, który napisałem do obliczania współczynnika Theila. Wprowadziłem dane i otrzymałem współczynniki takie jak na obrazku poniżej:
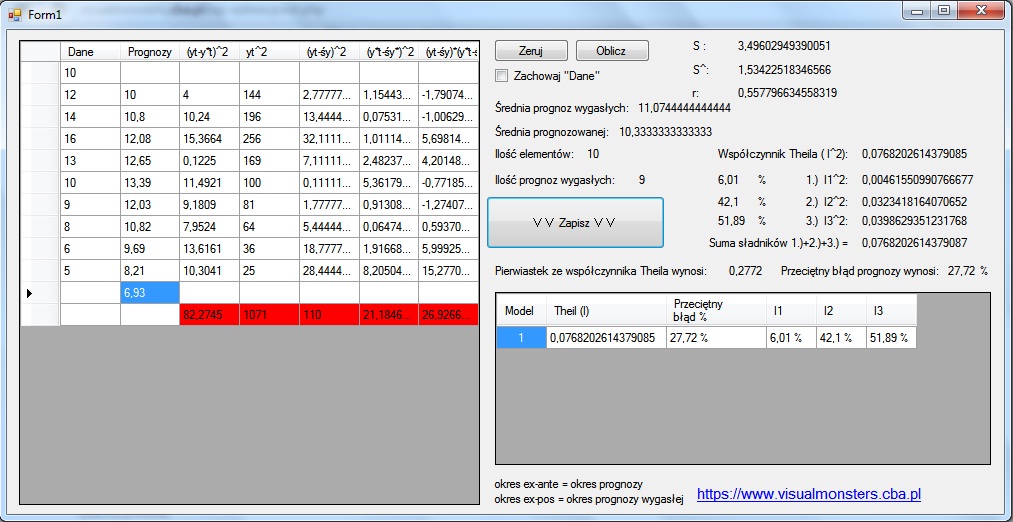
Dane wprowadziłem po lewej stronie, była to prognoza osiągnięta za pomocą modelu Holta(model 2). Jak widzimy, program sam oblicza współczynnik Theila jego składowe razem z procentami. Skorzystałem z metody Browna i wybrałem takie alfa, aby współczynnik Theila był podobny, to są współczynniki, jakie otrzymałem(model 1):
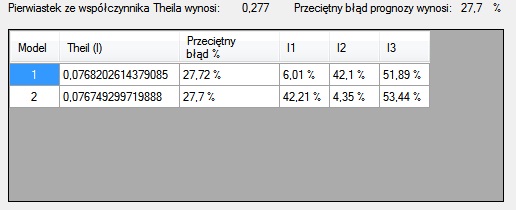
Jak widzimy, oba modele różnią się głównie wartościami I1 i I2 oznacza to, że model 1 ma mniejsze odchylenia średniej wartości prognozowanej od średniej wartości empirycznej, to znaczy, że średnia wartość błędu jest dla modelu 1 dużo mniejsza niż dla modelu 2. I2 świadczy o tym, jak duże są różnice między zmiennością prognozowaną i prognozą, czyli jak duża jest różnica między jedną zmiennością a drugą, wskaźnik ten świadczy o precyzji prognozowania. Czyli mimo tego, że różnice w błędzie były większe dla modelu drugiego, jego zmienność była bardziej zbliżona, co świadczy o większej precyzji prognozy ex-post a w rezultacie i prognozy ex-ante. Moim zdaniem lepszy jest model 2. Jeśli któreś z udziałów było by nieprzeciętnie wysokie tzn: stanowiło by 99% albo nieprzeciętnie niska 0% to rozkład taki świadczy o słabym dostosowaniu modelu i powinien być odrzucany w pierwszej kolejności. Mam nadzieje, że udało mi się coś wytłumaczyć, jeśli nie spróbujcie spojrzeć jeszcze raz na wzory dla I1, I2, I3 i ocenić skąd biorą się ich wartości i jak je interpretować. Jeśli wam się przyda, możecie pobrać program do obliczania współczynnika Theila i jego dekompozycji.
Program pobieramy tutaj:

