Często jest tak, że godzina, w jakiej gramy na giełdzie, biegamy lub rozgrywany jest mecz, ma duży wpływ na zachowanie naszego szeregu prognozowanego. Dane mogą podlegać różnym czynnikom w określonych godzinach i to często w bardzo regularny sposób. Jeśli obstawiamy giełdy walutowe, duży wpływ mogą na nie mieć godziny otwarcia handlu na giełdach światowych. Duże wzrosty lub spadki na giełdzie danego kraju ma duże znaczenie na cenę jego waluty. Jeśli miałeś czytelniku kiedykolwiek do czynienia z forexem lub giełdą surowców na pewno zauważyłeś, że ruch na nich odbywa się 24 godziny na dobę, pięć i pół dnia w tygodniu a na jego wahania wpływ ma bardzo wiele czynników. Utalentowani handlowcy rozumieją, że większe transakcje są skuteczne, jeśli są prowadzone, gdy działalność na rynku jest wysoka, a najlepiej unikać czasów, gdy handel jest lekki i że kursy walut są zmienne podczas różnych okresów. Na godziny handlu mają wpływ otwarcia i zamknięcia największych giełd światowych:

Program ma za zadanie wychwycić czas, w którym wahania kursu są największe i określić ich kierunek.
Zasadę tą można wykorzystać nie tylko na giełdzie, ale również w przyrodzie, technice lub statystyce. Ja przytaczam tutaj tylko taki przykład, ponieważ innym nie dysponuje. Przedstawię dzisiaj program wraz z kodem źródłowym (dla tych którzy chcieliby dostosować obliczenia do swoich potrzeb), który tą zależność będzie wychwytywał i wyświetlał na wykresie. Na giełdzie walutowej występują duże wahania błędów losowych, lecz dysponując tą wiedzą, zyskuje małą przewagę w naszej walce.
dane wykorzystane w przykładzie:
USDCHF60 (godzinowe), USDCHF1440 (dzienne), USDCHF43200 (miesięczne)
Program do analizy stref: TradingTiimeZones 1.0
O zakładkach:
Nie jest to, może najwybitniejsze narzędzie do prognozowania, ale daje obraz na to, jak i kiedy składać zlecenia. Obrazek powyżej wskazuje na godziny otwarcia giełd światowych w odpowiednich polskich godzinach, dla jednej waluty ruch na giełdzie w Londynie może mieć większe znaczenie niż ruch w innym miejscu, spowodowane jest to porą dnia w danym kraju, ich stosunkom międzynarodowym i wieloma innymi czynnikami. Poniżej znajdują się dwie rozwijalne zakładki. Jedna opisuje sposób budowy własnego programu do tej analizy, druga sposób działania mojego programu do tej analizy:
Jeśli program wam się nie podoba i uważacie, że zrobilibyście to lepiej lub chcielibyście coś do niego dodać, skorzystajcie z zakładki poniżej, aby zrobić sobie własny program. Jeśli jednak podoba wam się mój program, pokaże wam jak z niego skorzystać. Dysponuje danymi z MetaTradera 4 (do pobrania powyżej), lecz jeśli wiecie, jak zbudowany jest wasz plik z danymi, możecie bez problemu dodać go do programu i przeprowadzić na nim swoje obliczenia. Plik pobrany z MT4 wygląda następująco:
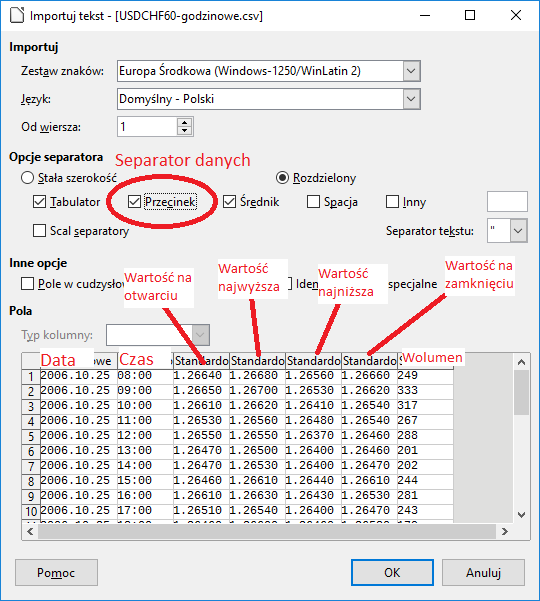
Jak takie dane pobrać opisuje w tym poście: https://visualmonsters.cba.pl/index.php/prognozowanie/pobieranie-danych-z-metatradera-4/
Warto takie dane trochę skrócić, ponieważ dane z 1971 są już bardzo nieaktualne (wystarczy edytować plik edytorem tekstu jak notatnik i usunąć część linijek ze starą datą). Kiedy wiemy jaki separator dzieli nasze dane, przechodzimy do programu i w sekcji Dane wybieramy nasze źródło danych: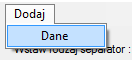
Nasze dane są jeszcze nie odseparowane, czasem separatorem jest przecinek, kropka albo tabulator (należy wtedy wpisać vbTab), separator należy wpisać w pole tekstowe i przycisnąć przycisk „Odśwież”:
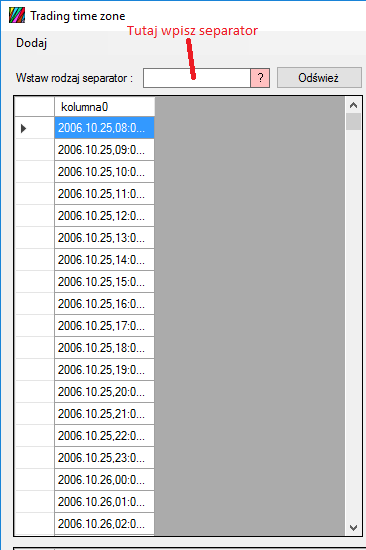
Dane zostaną oddzielone od siebie, a nam zostanie wybranie potrzebnych nam kolumn i operacji, które chcemy na nich przeprowadzić. Przypuśćmy, że chcemy dowiedzieć się, jak wyglądały zmiany wartości cen w poszczególnych dniach miesiąca. Czy zmiany bywały bardziej gwałtowne na początku miesiąca, czy może na jego końcu? Teraz jest czerwiec, więc czerwiec będzie nas interesował. Wybieramy pierwszą kolumnę z datą:
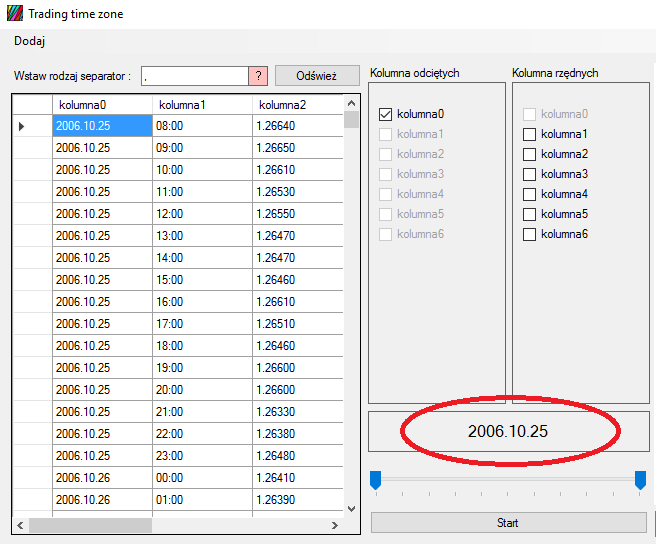
Na dole, nad przyciskiem start, pojawiła się data. Przy użyciu dwóch suwaków pod nią, należy tak ją zmienić, aby otrzymać tylko to, co nas interesuje, czyli miesiąc i dzień:
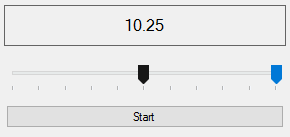
W tym miejscu wskazuje sposób, w jaki mają być posegregowane dane, czyli miesiąc i dzień. Teraz zajmijmy się kolumną rzędnych, aby określić czy dana cena w określonym czasie wzrastała, czy spadała, należy określić różnice między jej ceną zamknięcia a ceną otwarcia:
Należy więc w kolejności, najpierw wybrać kolumnę 5, a następnie kolumnę 2. Pod jeszcze niewygenerowanym wykresem pojawi się operacja matematyczna, która zostanie wykonana na kolumnach:
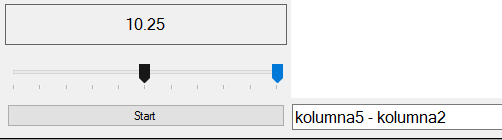
Program nie wykonuje skomplikowanych operacji matematycznych, ale aby dodać do siebie kolumny, należy zmienić znak na dodawanie, jeśli chcemy pomnożyć kolumny, należy użyć znaku gwiazdki * jeśli chcemy je podzielić, należy użyć znaku /. Kolejność wybierania kolumna ma znaczenie. Każda nowo dodana kolumna, dodaje się na końcu wzoru. Można dodawać nawiasy, zadania w nawiasach będą wykonywane jako pierwsze.

Można również dodać stałe wartości:

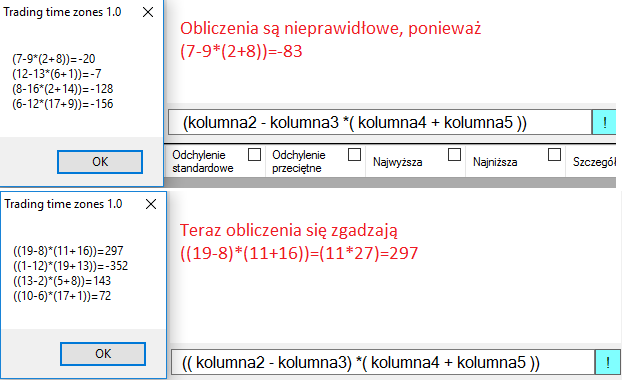
Cały algorytm zamieniający tekst na wzór jest bardzo skomplikowany, dlatego wprowadziłem możliwość sprawdzenia dokładności obliczeń, można to zrobić, wciskając niebieski znaczek z wykrzyknikiem ![]() , który generuje losowe liczby (z zakresu od 1 do 20) dla wybranych kolumn i przeprowadza cztery obliczenia.
, który generuje losowe liczby (z zakresu od 1 do 20) dla wybranych kolumn i przeprowadza cztery obliczenia.
Jeśli chcielibyśmy sprawdzić, czy wartości otwarcia w określonych godzinach są mniejsze od średniej, należy ją najpierw obliczyć ogólną średnią wartości otwarcia:
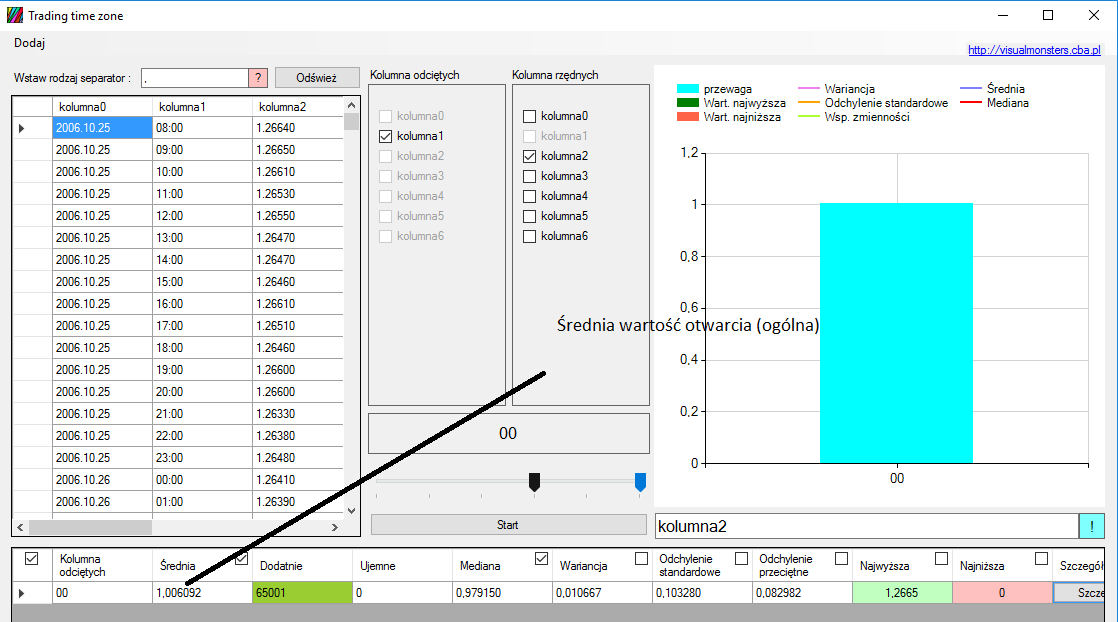
Należy teraz stworzyć wzór i uruchomić procedurę:
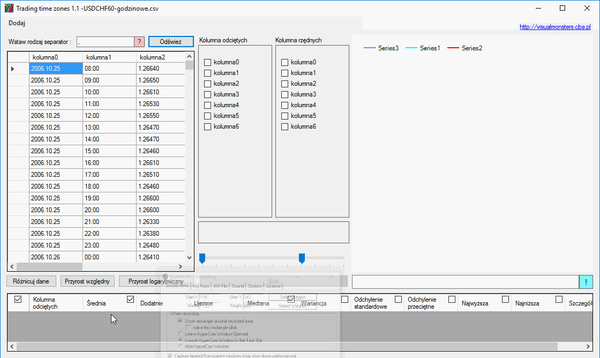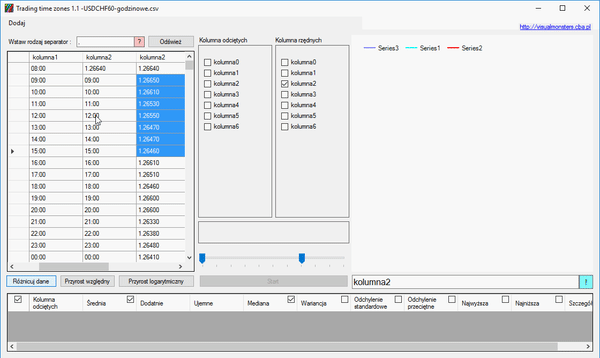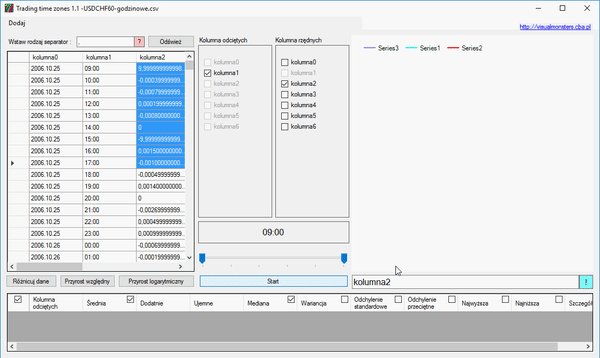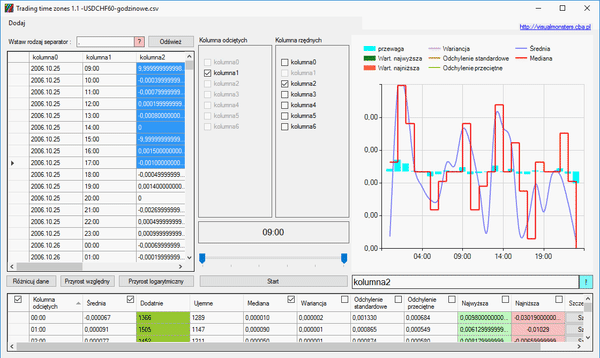
Wykres można powiększać, poprzez podwójne kliknięcie, na niego a do wykresu dodajemy i usuwamy elementy poprzez zaznaczanie poszczególnych pudełek (checkBox):
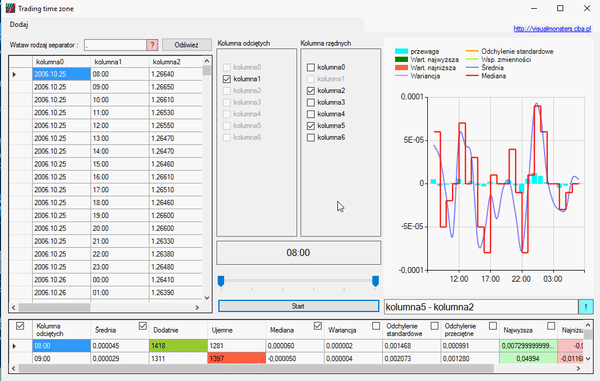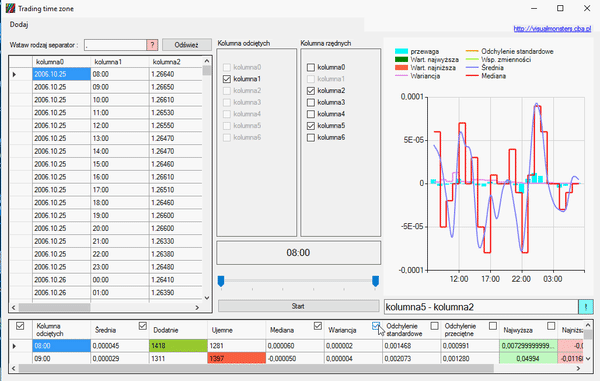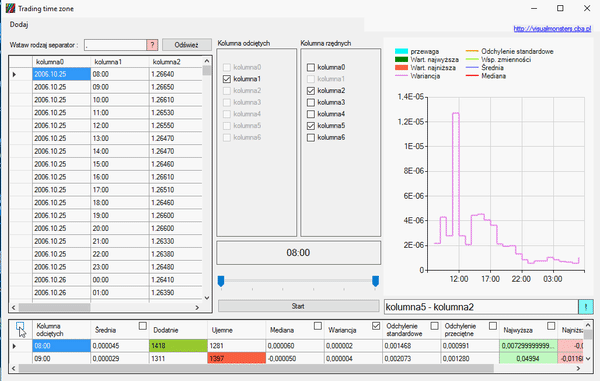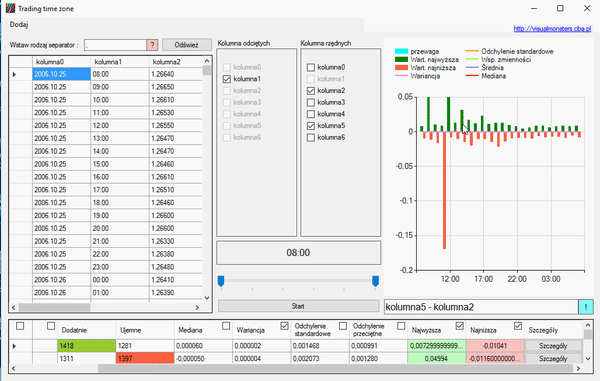
Co oznaczają poszczególne kolumny:
Kolumna odciętych- Oś X
Średnia – zwykła średnia arytmetyczna 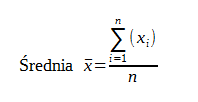
Mediana – wartość środkowa, wartość przeciętna, drugi kwartyl (segregujemy dane i wybieramy element znajdujący się w środku szeregu)
Wariancja – klasyczna miara zmienności.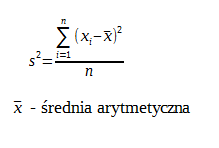 Intuicyjnie utożsamiana ze zróżnicowaniem zbiorowości
Intuicyjnie utożsamiana ze zróżnicowaniem zbiorowości
Odchylenie standardowe – 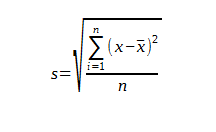 jest podstawową miarą zmienności obserwowanych wyników. Informuje o tym, na ile wyniki się „zmieniają”, tzn. czy rozrzut wyników wokół średniej jest niewielki czy wielki.
jest podstawową miarą zmienności obserwowanych wyników. Informuje o tym, na ile wyniki się „zmieniają”, tzn. czy rozrzut wyników wokół średniej jest niewielki czy wielki.
Odchylenie przeciętne – 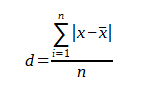 należy do miar zróżnicowania wyników, miar zmienności. Odchylenie przeciętne to średnia arytmetyczna z odchyleń wyników (wartość bezwzględna) od średniej. Wobec powyższego miara ta wskazuje jak średnio, przeciętnie wyniki odchylają się od średniej wartości, jest to przeciętne odchylanie się wyników.
należy do miar zróżnicowania wyników, miar zmienności. Odchylenie przeciętne to średnia arytmetyczna z odchyleń wyników (wartość bezwzględna) od średniej. Wobec powyższego miara ta wskazuje jak średnio, przeciętnie wyniki odchylają się od średniej wartości, jest to przeciętne odchylanie się wyników.
Reszta jest chyba jasna, o jednej wielkości nie mówiłem. Pokazuje ona pewien stosunek ilości dodatnich i ujemnych danych. Polega ona na wizualizacji przewagi spadków lub wzrostów, jeśli w jakimś okresie (np. godzinie) w danych jest przewaga wartości dodatnich, wtedy słupek będzie w górę. Słupek może przyjąć maksymalną wartość, taką jak przyjmuje najwyższa średnia, jeśli najwyższa średnia wynosi -15 wtedy słupek może być maksymalne wartości od -15 do 15. Słupki włącza się i wyłącza pierwszym pudełkiem. Kiedy wiemy już jaką maksymalną wartość przyjmuje średnia, należy wykonać działanie:
(((ilość wzrostów)-(ilość spadków))/((ilość wzrostów)+(ilość spadków)))*|najwyższa średnia|
Sortowanie kolumn lub usunięcie wierszy ma wpływ na wykres, aby to wam zobrazować, weźmy notowania dziennie i wybierzmy miesiąc i dzień. Powiedzmy, że chcemy wiedzieć, jak przebiegały zmiany tylko w dniach stycznia.
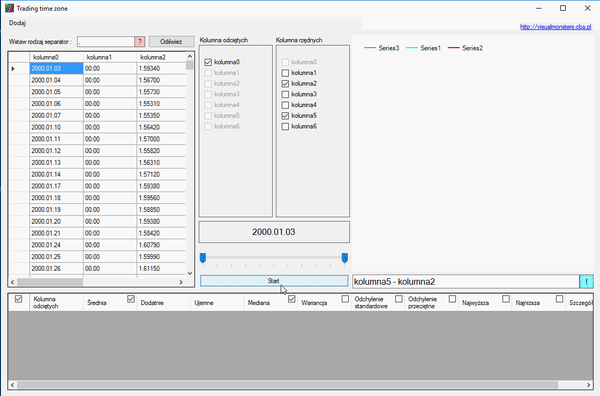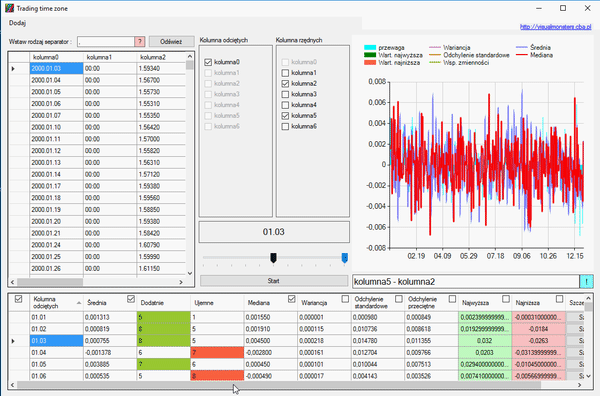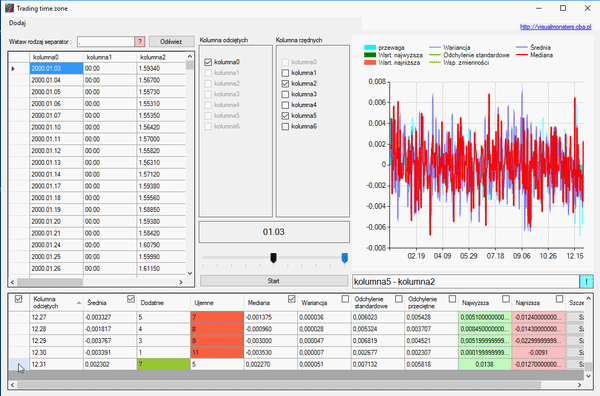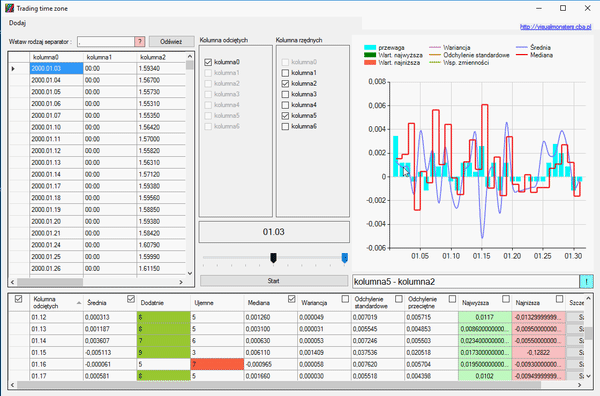
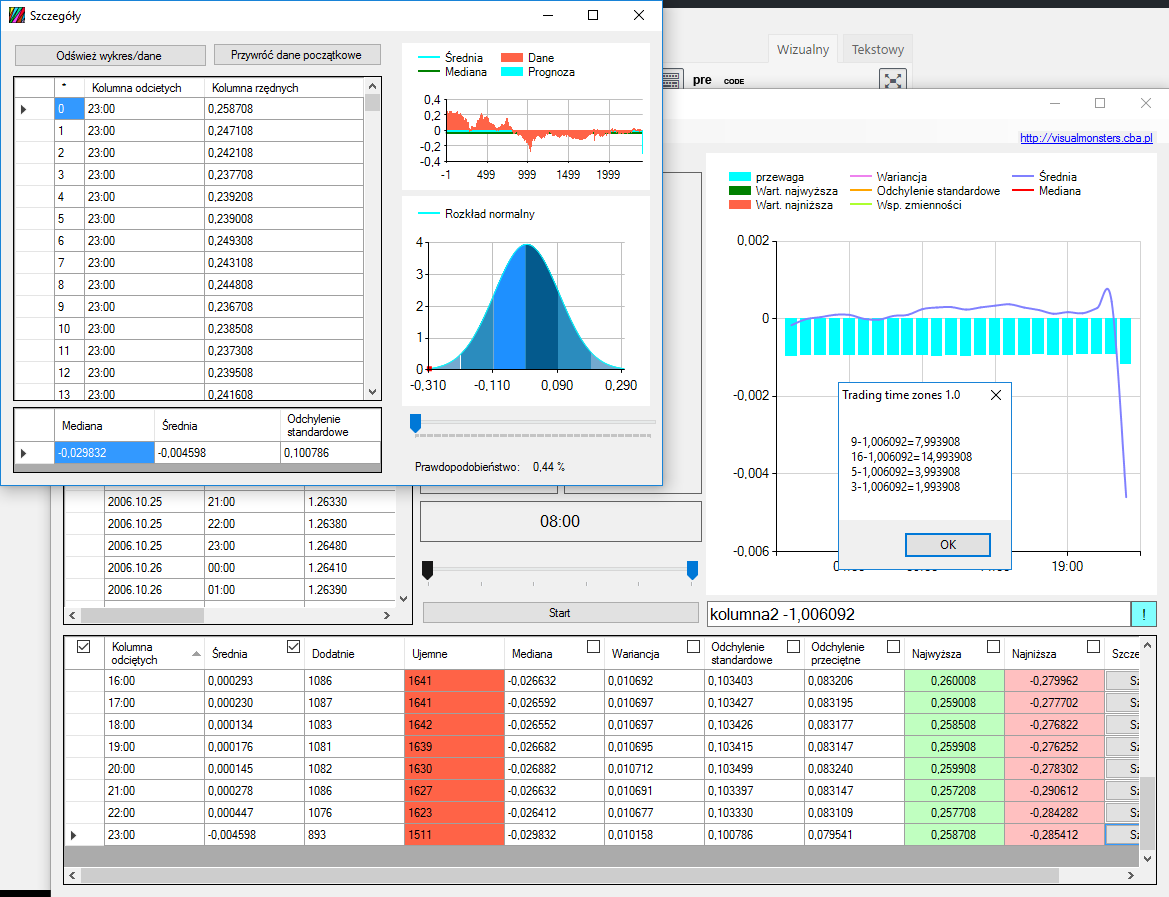
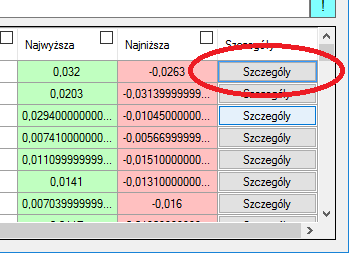
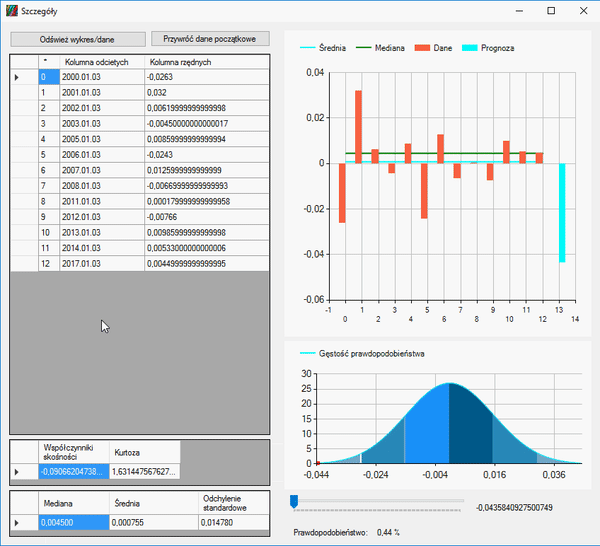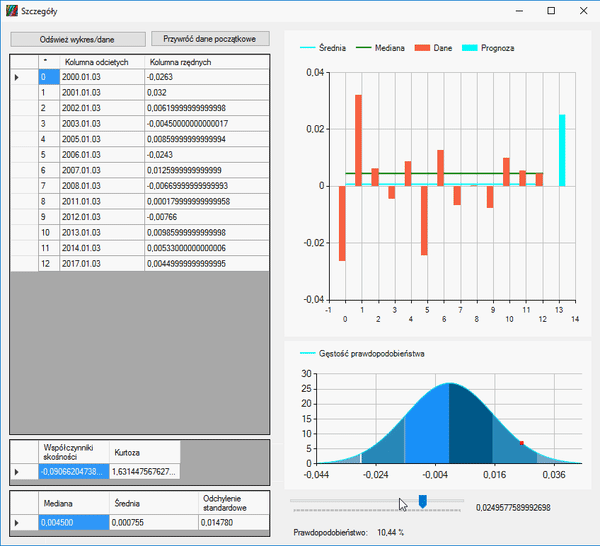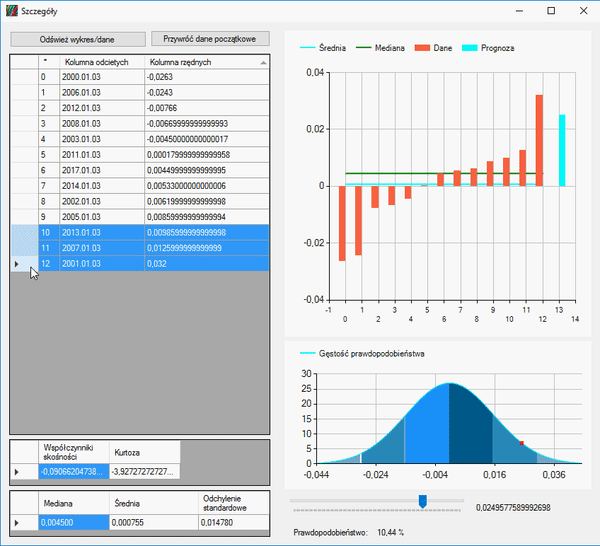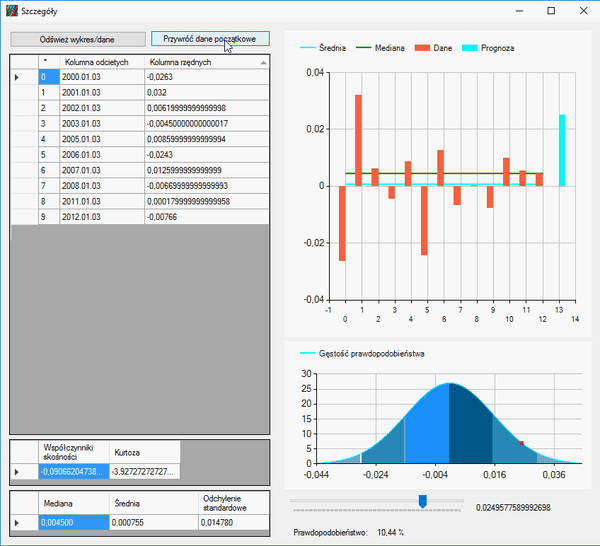
Jak widzicie w powyższym gifie, posegregowaliśmy wszystkie dane i skasowaliśmy resztę miesięcy, zostawiając tylko styczeń. Aby zaznaczyć wiesze, użyłem klawisza „Shift”, aby je usunąć, użyłem klawisza „Delete”. W każdym wierszu można podglądać elementy, z których się składają. Klikając przycisk „Szczegóły” na końcu wiersza, ukaże się nam okno analizy danych składowych.
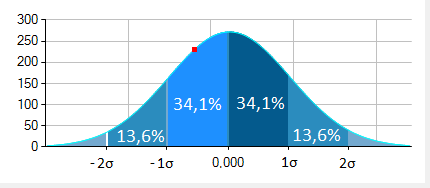
Jeśli nasze dane zdają się zmiennymi losowymi, współczynnik skośności jest bliski zeru, a kurtoza należy do przedziału od -3 do 3, możemy założyć, że zmienna losowa ma rozkład normalny i możemy skorzystać z reguły trzech sigm na wykresie gęstości, aby określić prawdopodobieństwo zajścia określonej wartości w przyszłości.
Jeśli jednak nasze dane nie spełniają powyższego warunku i kurtoza jest dużo wyższa, oznacza to, że nasze dane nie są skoncentrowane wokół średniej i prawdopodobieństwo wystąpienia określonej wartości będzie zaburzona, ponieważ:
Kurtoza informuje nas, jak duży jest „rozrzut” uzyskanych wyników, czy większość z nich skoncentrowana jest wokół średniej-wartości są zbliżone do wartości średniej. Jeżeli występuje znaczna koncentracja wyników wokół średniej (kurtoza przyjmuje wartość powyżej 0), możemy powiedzieć, że znaczna część wyników / obserwacji jest podobna, do siebie a obserwacji znacznie różniących się od średniej jest mało. Jeżeli występuje słaba koncentracja wyników wokół średniej (kurtoza przyjmuje wartość poniżej 0), możemy powiedzieć, że istnieje spora część wyników, które są znacznie oddalone od średniej.

Jeśli wartość kurtozy jest ujemna, można powiedzieć, że rozkład takich zmiennych jest spłaszczony (platokurtycznymi), a dla danych z dodatnią kurtozą, rozkład będzie bardziej spiczasty (leptokurtycznymi).
Współczynnik skośności przyjmuje wartość zero dla rozkładu symetrycznego, wartości ujemne dla rozkładów o lewostronnej asymetrii (wydłużone lewe ramię rozkładu) i wartości dodatnie dla rozkładów o prawostronnej asymetrii (wydłużone prawe ramię rozkładu).

Dodatkowo tak jak dane w poprzedniej formie, tak i te można edytować, usuwać i segregować.
Dane z tabeli, można sobie skopiować i przeprowadzić własne obliczenia, w Excelu czy gdzie tam chcecie. Wystarczy zaznaczyć interesujące nas elementy i skopiować przy użyciu klawiszy „Ctrl+C”. Tak jak poprzednio, wykres możemy powiększyć, klikając dwukrotnie na niego. Po co to wszystko na pewno się zapytacie. Przedstawię wam moje rozumowanie:

Namierzamy nasz miesiąc i dzień:
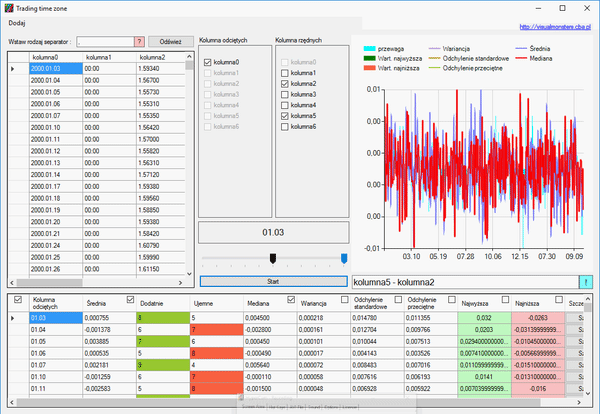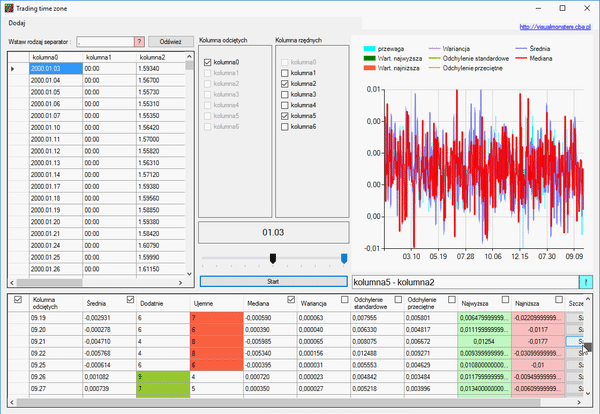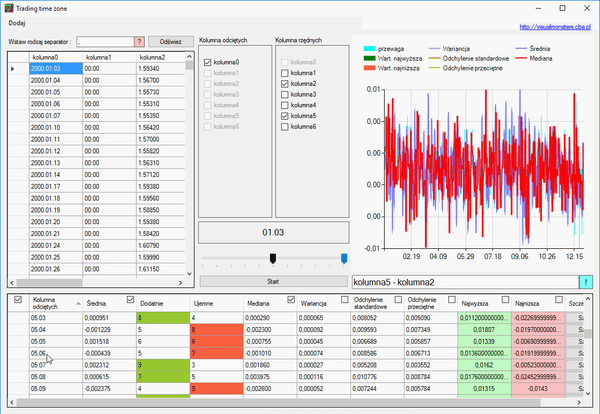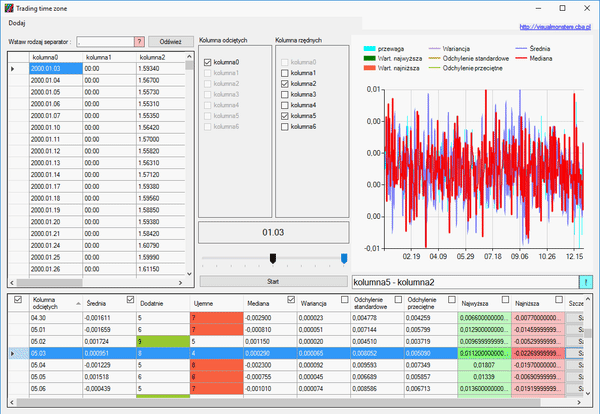
Otwieramy okno szczegółu i usuwamy ostatni rekord, ponieważ jego dane zamknięcia są nieaktualne, gdyż świeca ta się nie zamknęła, a dzień trwa. Naszym zadaniem jest określić tą wielkość:
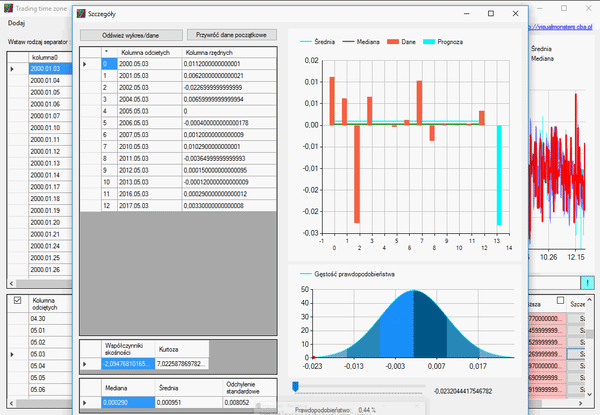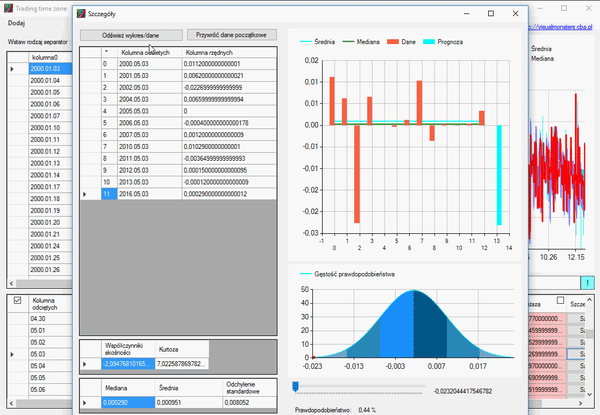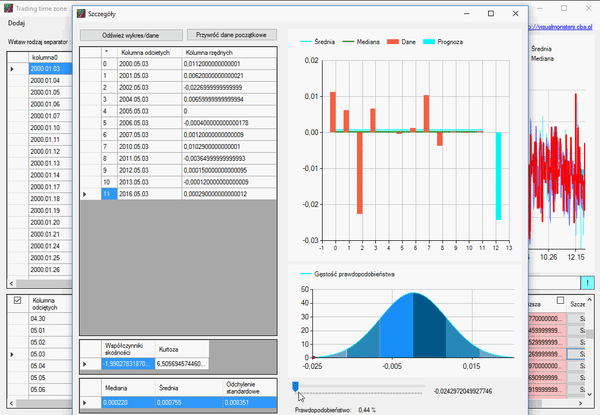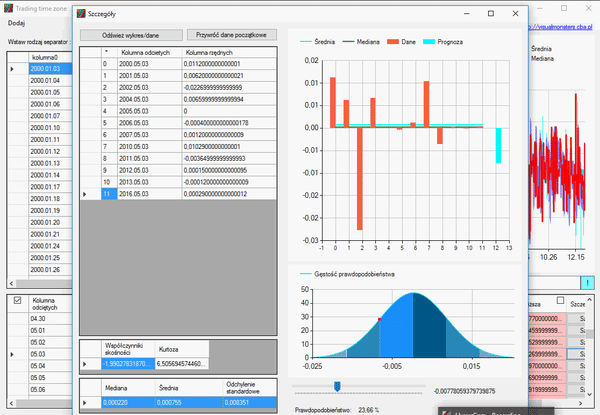
Jak widzimy, nasza kurtoza jest dosyć duża, a współczynnik skośności jest wyraźnie większy od zera. Dlatego nasza zmienna nie ma rozkładu normalnego. Jednak informacje, które otrzymaliśmy, pozwalają na postawienie następującej prognozy, na temat tego, jak zamknie się nasza świeca:
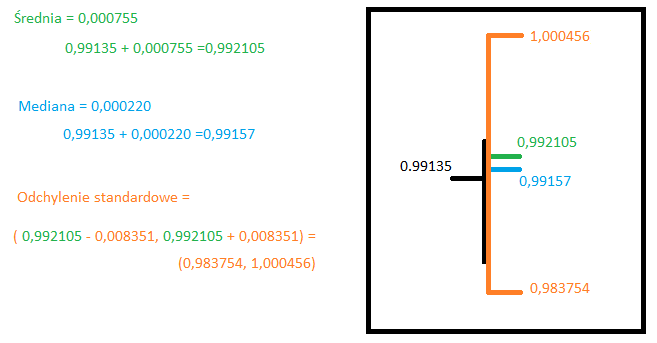
Oczywiście, gdy w grę wchodzą zmienne losowe, może się zdarzyć wszystko, ale taka analiza daje nam jakieś wyobrażenie, na to, jak dalej może rozwijać się nasza zmienna. Tutaj macie obrazek na wykresie jak to wyglądało:
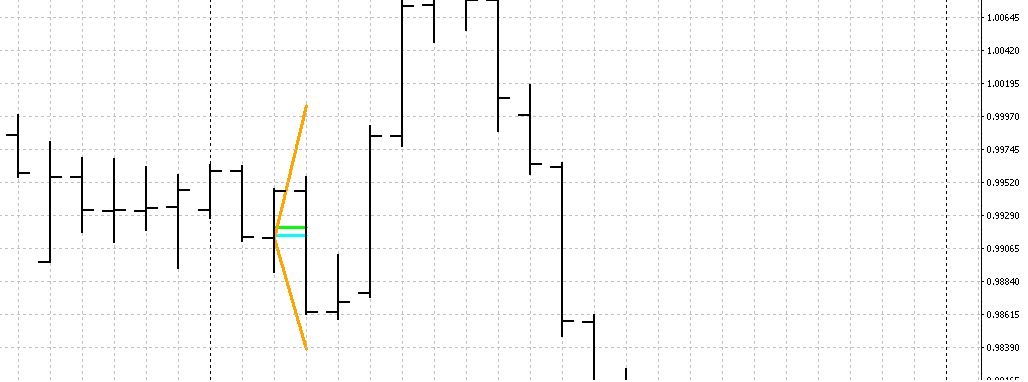
Zachęcam do przetestowania programu, mam nadzieje, że wam się przyda.
Mino, iż wcześniej na obrazkach tego nie ma, dodałem możliwość różnicowania wskazanych danych, wyliczenie przyrostów logarytmu i przyrostów względnych.
Jeśli chodzi o różnicowanie, to zapraszam do przeczytania artykułu: tutaj
Przyrost logarytmów i przyrost względny: tutaj
Aby wyliczyć takie przyrosty, należy wskazać kolumnę, w których mają być takie przyrosty policzone i wybrać odpowiedni przycisk:
W tej części zrobimy sobie program, który będzie robił takie same obliczenia jak ten powyżej. Program, który zrobimy, nie będzie tak skomplikowany w budowie, jak ten powyżej. Nasz będzie pobierał dane, dzielił je przy użyciu wskazanego separatora i obliczał tylko te elementy, które dodamy do kodu programu. Zaczynamy od budowy formy:

| Rodzaj elementu | Nazwa elementu | Ustawienia |
|---|---|---|
| Form | Form1 | Name: Form1 Text: Form1 Size: 777; 607 |
| DataGridView | DataGridView2 | Name: DataGridView2 Size: 366; 409 Location: 12; 12 |
| DataGridView | DataGridView1 | Name: DataGridView1 Size: 737; 129 Location: 12; 427 |
| Chart | Wykres | Name: Wykres Size: 365; 408 Location: 384; 13 |
| OpenFileDialog | OpenFileDialog1 | Name: OpenFileDialog1 |
Kiedy forma jest już przygotowana, należy utworzyć zmienne i uchwyt Form_load, który ustawi nam nasze elementy na starcie:
Public Class Form1
'Rodzaj separatora, oddzielającego dane
Dim separator As String = ","
'numer kolumny po której posegregujemy dane, zaczynając od 0
Dim kolumnaSegregacji As Integer = 1
'jeśli kolumnaSegregacji wymaga przycięcia z lewej lub prawej strony,
'należy określić wycięcie z lewej i z prawej, w innym wypadku zostawić
'zera, wzięcie musi znajdować się w przedziale długości kolumny segregującej
Dim początekUciecia As Integer = 0
Dim konicCiecia As Integer = 0
'zmienna przechowuje pobrane dane
Private ds As New DataSet()
Private Sub Form1_Load(sender As Object, e As EventArgs) Handles MyBase.Load
'tutaj ustawiamy zachowanie elementów na formie
''''''Rozciąganie elementów
DataGridView2.Anchor = AnchorStyles.Left Or AnchorStyles.Bottom Or AnchorStyles.Top
DataGridView1.Anchor = AnchorStyles.Left Or AnchorStyles.Bottom Or AnchorStyles.Right
Wykres.Anchor = AnchorStyles.Left Or AnchorStyles.Bottom Or AnchorStyles.Right Or AnchorStyles.Top
''''''Ułożenie legendy na wykresie
Wykres.Legends(0).Docking = Top
''''''Wygląd wykresu
'więcej elementów na osi X
Wykres.ChartAreas(0).AxisX.IntervalAutoMode = DataVisualization.Charting.IntervalAutoMode.VariableCount
'kolor linii
Wykres.ChartAreas(0).AxisX.MajorGrid.LineColor = Color.Silver
Wykres.ChartAreas(0).AxisY.MajorGrid.LineColor = Color.Silver
''''''Tabela
DataGridView2.AllowUserToAddRows = False 'użytkownik nie może dodawać wierszy
DataGridView1.AllowUserToAddRows = False
'tutaj wprowadzamy ilość kolumn w tabeli analiz
DataGridView1.ColumnCount = 4
'tutaj wprowadzamy nazwy kolumn w tabeli analiz
DataGridView1.Columns(0).Name = "Kolumna odciętych"
DataGridView1.Columns(1).Name = "Średnia"
DataGridView1.Columns(2).Name = "Mediana"
DataGridView1.Columns(3).Name = "Odchylenie standardowe"
''''''Wybieramy lokalizacje danych
OpenFileDialog1.Filter = "csv, txt files|*.csv;*.txt|All files (*.*)|*.*"
OpenFileDialog1.Title = "Wybierz źródło danych."
OpenFileDialog1.FileName = ""
'jeśli źródło danych zostało wybrane prawidłowo
With OpenFileDialog1
If .ShowDialog() = DialogResult.OK Then
'funkcja zwróci wiersze i kolumny danych do zmiennej DataTable
Dim myData As DataTable = TworzTabele(.FileName, separator)
' dodajemy je do zmiennej DataSet, z której będziemy pobierać dane do obróbki
ds.Tables.Add(myData)
'wyświetli podzielone dane w tabeli
DataGridView2.DataSource = myData
End If
End With
'Segreguje dane wedłóg wskazanej kolumny
segregacja(kolumnaSegregacji)
End Sub
End Class
Wszystko starałem się opisać w kodzie, segregacja i pobór danych do DataSet jeszcze nie działa, ale zaraz się tym zajmiemy. Form_Load posłuży nam do ustawienia naszych elementów formy i przygotowania tabel, głównie tej wyświetlającej analiz. Jeśli chcielibyśmy dodać kolumnę, do tabeli z analizami należy zwiększyć ColumnCount i wprowadzić jej nazwę:
DataGridView1.ColumnCount = 5
'tutaj wprowadzamy nazwy kolumn w tabeli analiz
DataGridView1.Columns(0).Name = "Kolumna odciętych"
DataGridView1.Columns(1).Name = "Średnia"
DataGridView1.Columns(2).Name = "Mediana"
DataGridView1.Columns(3).Name = "Odchylenie standardowe"
DataGridView1.Columns(4).Name = "Wariancja"
Należy zapamiętać która kolumna za co odpowiada, przyda się to później, pierwsza kolumna jest wymagana, w tym miejscu możemy również dodać formatowanie kolumn. Zajmiemy się teraz pobieraniem danych.
Private Function TworzTabele(ByVal SciezkaDoPliku As String, ByVal separator As String) As DataTable
Dim Tabela As DataTable = New DataTable("MyTable")
Dim i As Integer
Dim wiersze As DataRow
Dim wartosc As String()
Dim f As IO.File = Nothing
Dim rodzajkodu As New IO.StreamReader(SciezkaDoPliku, System.Text.Encoding.UTF8)
Try
wartosc = rodzajkodu.ReadLine().Split(separator)
For i = 0 To wartosc.Length() - 1
Tabela.Columns.Add(New DataColumn("kolumna" & i))
Next
wiersze = Tabela.NewRow
For i = 0 To wartosc.Length() - 1
wiersze.Item(i) = wartosc(i).ToString
Next
Tabela.Rows.Add(wiersze)
While rodzajkodu.Peek() <> -1
wartosc = rodzajkodu.ReadLine().Split(separator)
wiersze = Tabela.NewRow
For i = 0 To wartosc.Length() - 1
wiersze.Item(i) = wartosc(i).ToString
Next
Tabela.Rows.Add(wiersze)
End While
Catch ex As Exception
MsgBox("Błąd przy tworzeniu tabeli: " & ex.Message)
Return New DataTable("Empty")
Finally
rodzajkodu.Close()
End Try
Return Tabela
End Function
Funkcja ta pobiera wiersze pliku, separuje je, wybranym wcześniej separatorem i tworzy wiersze tabeli, należy zwrócić tylko uwagę na rodzaj użytego dekodera, jeśli dane są źle pobierane, nie występuje polskie znaki, lub zamiast liter są kwadraciki, lub znaki zapytania, należy zmienić
System.Text.Encoding.UTF8 na System.Text.Encoding.Default
lub wybrać odpowiedni z listy dostępnych. Teraz gdy mamy stworzony DataSet, należy wydobyć z niego potrzebne nam informacje, lub go sformatować, a potem pobrać informacje (zróźnicować, wyliczyć przyrosty itp.).
Dim slownik As New Dictionary(Of String, List(Of Double))
Private Sub segregacja(ByVal kolumnaSegregacji As Integer)
konicCiecia = ds.Tables.Item(0).Rows(0).Item(kolumnaSegregacji).length - konicCiecia - początekUciecia
'Przykład różnicowania danych przed wizualizacją
'''''Przykład dla danych pobranych z MT4
' For j As Integer = 0 To 0 'rząd różnicowania
' For i As Integer = 1 To ds.Tables.Item(0).Rows.Count - 1
' ds.Tables.Item(0).Rows(i).Item(2) = Replace(ds.Tables.Item(0).Rows(i).Item(2), ".", ",") - Replace(ds.Tables.Item(0).Rows(i - 1).Item(2), ".", ",")
' ds.Tables.Item(0).Rows(i).Item(3) = Replace(ds.Tables.Item(0).Rows(i).Item(3), ".", ",") - Replace(ds.Tables.Item(0).Rows(i - 1).Item(3), ".", ",")
' ds.Tables.Item(0).Rows(i).Item(4) = Replace(ds.Tables.Item(0).Rows(i).Item(4), ".", ",") - Replace(ds.Tables.Item(0).Rows(i - 1).Item(4), ".", ",")
' ds.Tables.Item(0).Rows(i).Item(5) = Replace(ds.Tables.Item(0).Rows(i).Item(5), ".", ",") - Replace(ds.Tables.Item(0).Rows(i - 1).Item(5), ".", ",")
' Next
' ds.Tables.Item(0).Rows(0).Delete()
' Next
'Listujemy wszystkie elementy Dataset
For i As Integer = 0 To ds.Tables.Item(0).Rows.Count - 1
Dim sort As String = ds.Tables.Item(0).Rows(i).Item(kolumnaSegregacji).ToString.Substring(początekUciecia, konicCiecia)
'''''Przykład dla danych pobranych z MT4
Dim open As Double = Replace(ds.Tables.Item(0).Rows(i).Item(2), ".", ",")
Dim hight As Double = Replace(ds.Tables.Item(0).Rows(i).Item(3), ".", ",")
Dim low As Double = Replace(ds.Tables.Item(0).Rows(i).Item(4), ".", ",")
Dim close As Double = Replace(ds.Tables.Item(0).Rows(i).Item(5), ".", ",")
'''''''''''''
'Wykonaj operacje na danych
Dim wartosc As Double = close - open
'Dodaj dane do słownika
If slownik.ContainsKey(sort) = True Then
slownik(sort).Add(wartosc)
Else
'jeśli klucz nie istnieje
Dim ListaWartosci As New List(Of Double)
ListaWartosci.Add(wartosc)
slownik.Add(sort, ListaWartosci)
End If
Next
operacjeNaSlowniku()
End Sub
Dane pobrane z Dataset umieszczamy w słowniku (Dictionary), jest on specyficznym obiektem, który zbudowany jest z dwóch składowych, klucza i wartości. Klucz jest e naszym przypadku ciągiem znakowym (string) i nie może być w słowniku dwóch identycznych kluczy, do każdego klucza przypisana jest lista wartości, posegregowanych według sformatowanej wcześniej kolumny. W powyższym kodzie dodałem przykład operacji różnicowania wartości przed ich dodaniem do słownika. Ja używam danych z MT4, dlatego powyższy przykład ma formatowanie takie jak dane pobrane z pliku historii tego właśnie programu. Wasz może różnić się nieco, dlatego należy najpierw sprawdzić swoje dane przed wykonaniem tej metody, aby nie działać na ślepo. Dane pobrane z MT4 mają kropkę, zamiast przecinku dlatego należy po pobraniu danych z DataSet zamienić kropkę na przecinek, aby była możliwość zamiany ich z typu String na typ Double. Jeśli chcielibyśmy wyliczyć średnią ze wszystkich elementów open, low, hight, close, wtedy nasza operacja na danych wyglądałaby następująco:
'Wykonaj operacje na danych Dim wartosc As Double = (close + open + low + hight) / 4
Etap ten służy sformatowaniu naszych danych i pobraniu tylko wybranych elementów. Kiedy już dane zostaną sformatowane, niechciane elementy pominięte, przyszedł czas na obliczenia.
Private Sub operacjeNaSlowniku()
' dla każdego klucza w słowniku
For Each klucze As KeyValuePair(Of String, List(Of Double)) In slownik
'dodajemy wiersz do tabeli analiz
DataGridView1.Rows.Add()
DataGridView1.Rows(DataGridView1.Rows.Count - 1).Cells(0).Value = klucze.Key
Dim suma As Double = 0
'Średnia
Dim srednia As Double = 0
For i As Integer = 0 To klucze.Value.Count - 1
suma += klucze.Value(i)
Next
srednia = suma / klucze.Value.Count
DataGridView1.Rows(DataGridView1.Rows.Count - 1).Cells(1).Value = srednia
'Mediana
klucze.Value.Sort() 'sortuje listę
If klucze.Value.Count Mod 2 = 0 Then
DataGridView1.Rows(DataGridView1.Rows.Count - 1).Cells(2).Value =
(klucze.Value(klucze.Value.Count / 2) + klucze.Value((klucze.Value.Count / 2) + 1)) / 2
Else
DataGridView1.Rows(DataGridView1.Rows.Count - 1).Cells(2).Value =
klucze.Value(Math.Ceiling(klucze.Value.Count / 2))
End If
'Odchylenie standardowe
Dim wariancja As Double = 0
For i As Integer = 0 To klucze.Value.Count - 1
wariancja += (klucze.Value(i) - srednia) ^ 2
Next
wariancja = wariancja / klucze.Value.Count
DataGridView1.Rows(DataGridView1.Rows.Count - 1).Cells(3).Value = Math.Sqrt(wariancja)
'Wariancja
DataGridView1.Rows(DataGridView1.Rows.Count - 1).Cells(4).Value = wariancja
Next
TworzenieWykresu()
End Sub
Oznaczenie
DataGridView1.Rows(DataGridView1.Rows.Count - 1)
Oznacza ostatni wiersz z kolekcji, jeśli umożliwimy użytkownikowi dodawanie wierszy, należy zmienić tę wartość z -1 na -2. Klucze ze słownika wyświetlamy za pomocą Klucze.Key a lista wartości znajduje się w klucze.Value, aby wyświetlić konkretny element z listy wartości, należy użyć słowa klucze.Value(indeks). Ostatnim etapem, jest wyświetlenie naszych danych w wykresie:
Private Sub TworzenieWykresu()
Wykres.ChartAreas(0).AxisY.LabelStyle.Format = "N2"
Wykres.Series.Clear()
Dim min As Double = Double.MaxValue
Dim max As Double = Double.MinValue
'średnie
Wykres.Series.Add(0)
Wykres.Series(0).Name = "Średnia"
Wykres.Series(0).Color = Color.FromArgb(128, 128, 255)
Wykres.Series(0).BorderWidth = 2
Wykres.Series(0).ChartType = DataVisualization.Charting.SeriesChartType.Line
For i As Integer = 0 To DataGridView1.Rows.Count - 1
Dim srednia As Double = DataGridView1.Rows(i).Cells(1).Value
Wykres.Series(0).Points.AddXY(DataGridView1.Rows(i).Cells(0).Value, srednia)
Next
'Mediana
Wykres.Series.Add(1)
Wykres.Series(1).Name = "Mediana"
Wykres.Series(1).Color = Color.Tomato
Wykres.Series(1).BorderWidth = 2
Wykres.Series(1).ChartType = DataVisualization.Charting.SeriesChartType.Line
For i As Integer = 0 To DataGridView1.Rows.Count - 1
Dim Mediana As Double = DataGridView1.Rows(i).Cells(2).Value
Wykres.Series(1).Points.AddXY(DataGridView1.Rows(i).Cells(0).Value, Mediana)
Next
'odchylenie standardowe
' Wykres.Series.Add(2)
' Wykres.Series(2).Name = "Odchylenie standardowe"
' Wykres.Series(2).Color = Color.Orange
' Wykres.Series(2).BorderWidth = 2
' Wykres.Series(2).ChartType = DataVisualization.Charting.SeriesChartType.StepLine
' For i As Integer = 0 To DataGridView1.Rows.Count - 1
' Dim SDK As Double = DataGridView1.Rows(i).Cells(3).Value
' Wykres.Series(2).Points.AddXY(DataGridView1.Rows(i).Cells(0).Value, SDK)
' Next
'Wartości najwyzsze
' Wykres.Series.Add(3)
' Wykres.Series(3).Name = "Najwyższe"
' Wykres.Series(3).Color = Color.Green
' Wykres.Series(3).BorderWidth = 2
' Wykres.Series(3).ChartType = DataVisualization.Charting.SeriesChartType.Column
' For i As Integer = 0 To DataGridView1.Rows.Count - 1
' Dim najwyzszy As Double = slownik(DataGridView1.Rows(i).Cells(0).Value).Item(0)
' For j As Integer = 0 To slownik(DataGridView1.Rows(i).Cells(0).Value).Count - 1
' If najwyzszy < slownik(DataGridView1.Rows(i).Cells(0).Value).Item(j) Then
' najwyzszy = slownik(DataGridView1.Rows(i).Cells(0).Value).Item(j)
' End If
' Next
' Wykres.Series(3).Points.AddXY(DataGridView1.Rows(i).Cells(0).Value, najwyzszy)
' Next
'Wartości najniższe
' Wykres.Series.Add(4)
' Wykres.Series(4).Name = "Najniższe"
' Wykres.Series(4).Color = Color.Red
' Wykres.Series(4).BorderWidth = 2
' Wykres.Series(4).ChartType = DataVisualization.Charting.SeriesChartType.Column
'
'For i As Integer = 0 To DataGridView1.Rows.Count - 1
'Dim najnizszy As Double = slownik(DataGridView1.Rows(i).Cells(0).Value).Item(0)
'For j As Integer = 0 To slownik(DataGridView1.Rows(i).Cells(0).Value).Count - 1
'If najnizszy > slownik(DataGridView1.Rows(i).Cells(0).Value).Item(j) Then
'najnizszy = slownik(DataGridView1.Rows(i).Cells(0).Value).Item(j)
'End If
'Next
'Wykres.Series(4).Points.AddXY(DataGridView1.Rows(i).Cells(0).Value, najnizszy)
'Next
For i As Integer = 0 To Wykres.Series.Count - 1
If Wykres.Series(i).Enabled Then
For j As Integer = 0 To Wykres.Series(i).Points.Count - 1
Dim value As Double = Wykres.Series(i).Points(j).YValues(0)
If value < min Then min = value
If value > max Then max = value
Next
End If
Next
Wykres.ChartAreas(0).AxisY.Minimum = min
Wykres.ChartAreas(0).AxisY.Maximum = max
End Sub
Zamaskowałem, niektóre elementy, ponieważ te elementy powinny być wyświetlane osobno. Pozycja, w której dodajemy dane, ma bardzo duże znaczenie. Dodawanie serii do wykresu powinniśmy przeprowadzić w taki sposób, aby dane, wyświetlane na wykresie nie zasłaniały się nawzajem. Dodanie najpierw wykresu liniowego, a następnie wykresu kolumnowego spowoduje zasłonięcie tego pierwszego. Dane wyświetlane na wykresie, pobierane są z tabeli umieszczonej na formie. Ma to dwojakie znaczenie, możemy zmienić nasze dane i dodać przycisk odświeżania, który będzie reagował na zmianę danych w tabeli, dodanie własnych kolumn itp.
Private Sub DataGridView1_ColumnHeaderMouseClick(sender As Object, e As DataGridViewCellMouseEventArgs) Handles DataGridView1.ColumnHeaderMouseClick
TworzenieWykresu()
End Sub
Efekt:
Daje to możliwość reakcji wykresu na zmianę sortowania tabeli. Mam nadzieję, że wam się to przyda. Projekt do pobrania poniżej


1 komentarz
Artykuł przyjemny dla oka i użyteczny. Na innych stronach formatowanie tekstu czasami woła o pomstę do nieba. Jak widzę ścianę tekstu to po prostu wychodzę. Tutaj odpowiednie odstępy i treść. Na pewno będę zaglądał tutaj częściej 🙂